AE 16: Traffic fines and electoral politics - regression with a single predictor
Suggested answers
In this application exercise we will replicate part of the analysis from Playing politics with traffic fines: Sheriff elections and political cycles in traffic fines revenue.1 The abstract of the article states:
The political budget cycle theory has extensively documented how politicians manipulate policies during election years to gain an electoral advantage. This paper focuses on county sheriffs, crucial but often neglected local officials, and investigates their opportunistic political behavior during elections. Using a panel data set covering 57 California county governments over four election cycles, we find compelling evidence of traffic enforcement policy manipulation by county sheriffs during election years. Specifically, a county’s per capita traffic fines revenue is 9% lower in the election than in nonelection years. The magnitude of the political cycle intensifies when an election is competitive. Our findings contribute to the political budget cycle theory and provide timely insights into the ongoing debate surrounding law enforcement reform and local governments’ increasing reliance on fines and fees revenue.
Our goal is to better understand how politicians manipulate government policy during electoral years in an effort to gain an electoral advantage.
We will use {tidyverse} and {tidymodels} for data exploration and modeling, respectively.
The replication data file can be found in data/traffic_fines_lite.csv. Let’s load the data and take a look at the first few rows.2
traffic_fines <- read_csv("data/traffic_fines_lite.csv")Rows: 1025 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): county_name, elec_dummy
dbl (4): year, county_code, vehicle_code_fines_i_p, med_inc
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.skim(traffic_fines)| Name | traffic_fines |
| Number of rows | 1025 |
| Number of columns | 6 |
| _______________________ | |
| Column type frequency: | |
| character | 2 |
| numeric | 4 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| county_name | 0 | 1 | 4 | 15 | 0 | 57 | 0 |
| elec_dummy | 0 | 1 | 2 | 3 | 0 | 2 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| year | 0 | 1 | 2011.49 | 5.19 | 2003 | 2007.00 | 2011.00 | 2016.00 | 2020.00 | ▇▆▇▆▇ |
| county_code | 0 | 1 | 29.37 | 16.86 | 1 | 15.00 | 29.00 | 44.00 | 58.00 | ▇▇▇▇▇ |
| vehicle_code_fines_i_p | 0 | 1 | 3.90 | 7.23 | 0 | 0.43 | 2.16 | 4.87 | 108.73 | ▇▁▁▁▁ |
| med_inc | 0 | 1 | 55598.49 | 17114.92 | 28533 | 43237.00 | 52078.00 | 63398.00 | 139462.00 | ▇▇▂▁▁ |
Estimate a model with a continuous explanatory variable
First, we are going to investigate the relationship between a county’s median household income and the per capita traffic fines revenue (adjusted for inflation) (simply referred to as per capita traffic fines revenue). Our working theory is that counties with higher median household income will have lower per capita traffic fines revenue because they can draw on other sources of revenue (e.g. property taxes, sales tax, income tax).
Question: Based on our research focus, which variable is the response variable?
vehicle_code_fines_i_p
Demo: Visualize the relationship between median household income and per capita traffic fines revenue.
ggplot(
data = traffic_fines,
mapping = aes(x = med_inc, y = vehicle_code_fines_i_p)
) +
geom_point()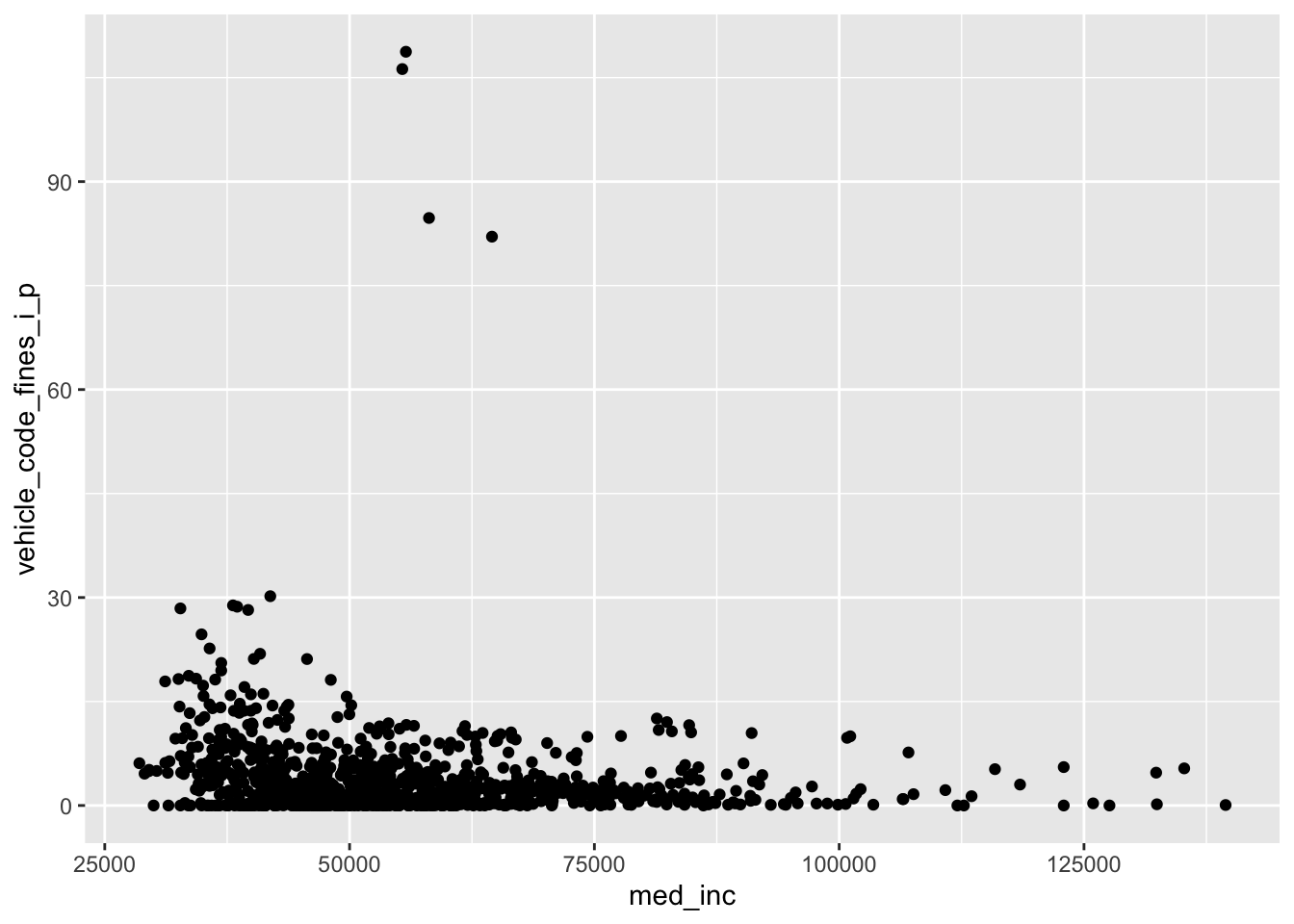
Correlation
Demo: What is the correlation between median household income and per capita traffic fines revenue?
Define the model
This is the population model that explains the relationship between median household income and per capita traffic fines revenue.
\[ \text{traffic fines} = \beta_0 + \beta_1 \times \text{median household income} \]
Demo: Fit the linear regression model and display the results.
Use tidy() to print the model output in a readable, tabular format.
fines_inc_fit <- linear_reg() |>
fit(vehicle_code_fines_i_p ~ med_inc, data = traffic_fines)
tidy(fines_inc_fit)# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 6.93 0.762 9.10 4.45e-19
2 med_inc -0.0000546 0.0000131 -4.17 3.35e- 5# visualize the model
ggplot(
data = traffic_fines,
mapping = aes(x = med_inc, y = vehicle_code_fines_i_p)
) +
geom_point() +
geom_smooth(method = "lm")`geom_smooth()` using formula = 'y ~ x'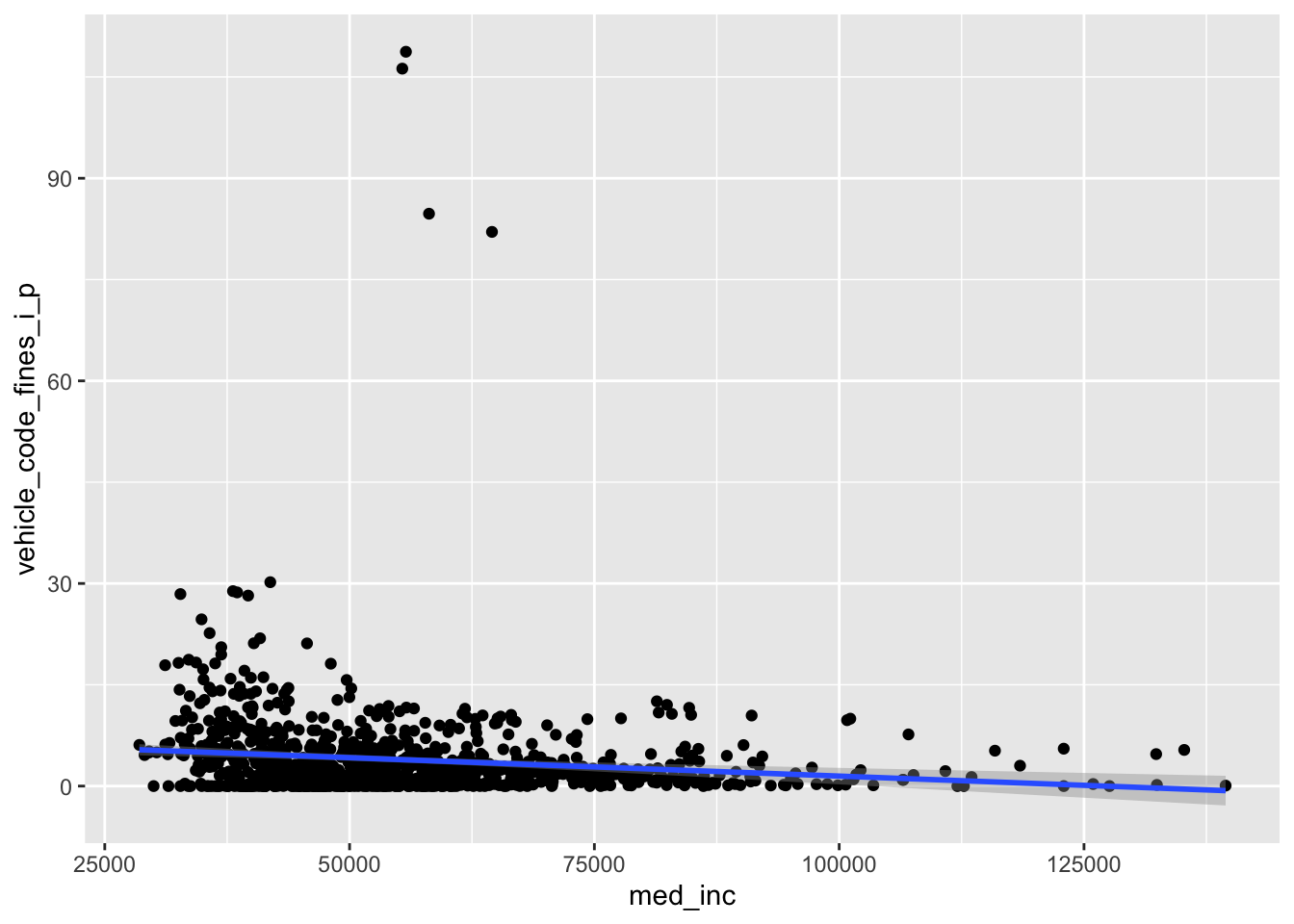
\[ \widehat{\text{traffic fines}} = 6.93 - 0.0000546 \times \text{median household income} \]
Your turn: Interpret the slope and the intercept in the context of the data.
Intercept: Counties with a median household income of $0, on average, earn $6.93 per capita in traffic fines revenue.
-
Slopes: For each additional dollar of median household income, the per capita traffic fines revenue is lower by $0.0000546, on average.
Alternative: For each additional $1,000 of median household income, the per capita traffic fines revenue is lower by $0.0546, on average.
Generate predictions
Your turn: What is the estimated per capita traffic fines revenue for a county with $80,000 median household income? What about a county with $15,000 median household income?
Use predict() to generate predicted values from a fitted model. Provide the new data in a data frame as the new_data argument.
Be warned that even though we can generate predictions for any value of median household income, it is not always appropriate to do so. We should only generate predictions for values of the predictor variable that are within the range of the data used to fit the model (interpolation). $15,000 is outside of the range of the data (extrapolation).
Conduct a hypothesis test
Your turn: State the hypotheses to evaluate the relationship between median household income and per capita traffic fines revenue.
-
Null hypothesis: There is no linear relationship between median household income and per capita traffic fines revenue.
\[H_0: \beta_1 = 0\]
-
Alternative hypothesis: There is some linear relationship between median household income and per capita traffic fines revenue.
\[H_A: \beta_1 \neq 0\]
Demo: Use permutation-based methods to conduct the hypothesis test.
# calculate observed fit
obs_fit <- traffic_fines |>
specify(vehicle_code_fines_i_p ~ med_inc) |>
fit()
# generate permuted null distribution
null_dist <- traffic_fines |>
specify(vehicle_code_fines_i_p ~ med_inc) |>
hypothesize(null = "independence") |>
generate(reps = 1000, type = "permute") |>
fit()
# visualize and calculate p-value
visualize(null_dist) +
shade_p_value(obs_fit, direction = "both")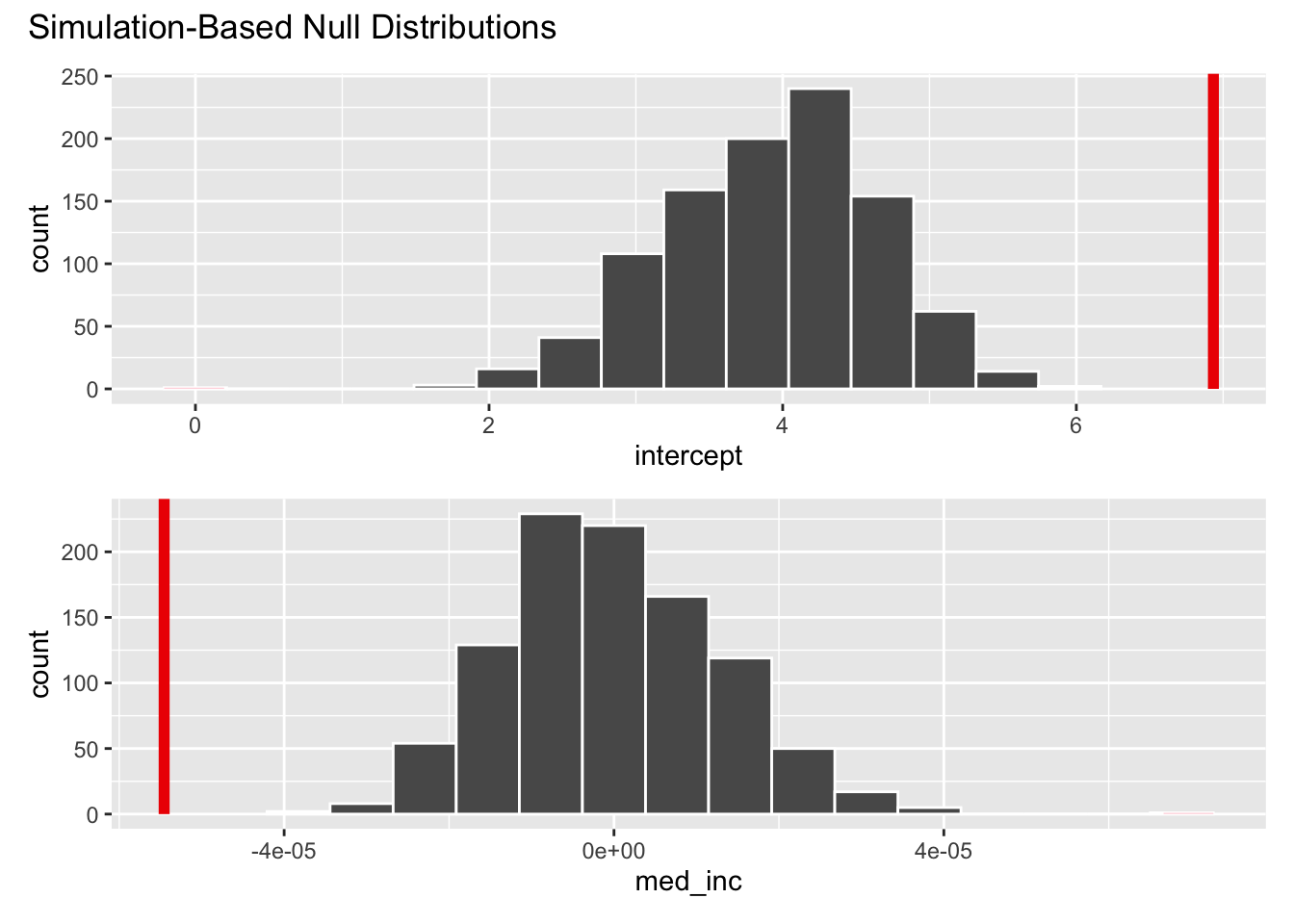
get_p_value(null_dist, obs_fit, direction = "both")Warning: Please be cautious in reporting a p-value of 0. This result is an approximation
based on the number of `reps` chosen in the `generate()` step.
ℹ See `get_p_value()` (`?infer::get_p_value()`) for more information.
Please be cautious in reporting a p-value of 0. This result is an approximation
based on the number of `reps` chosen in the `generate()` step.
ℹ See `get_p_value()` (`?infer::get_p_value()`) for more information.# A tibble: 2 × 2
term p_value
<chr> <dbl>
1 intercept 0
2 med_inc 0Your turn: Interpret the \(p\)-value in context of the data and the research question. Use a significance level of 5%.
Add response here. If in fact the true relationship between median household income and per capita traffic fines revenue is zero, the probability of observing a relationship as strong as the one in the data is less than 0.001. Since this is less than 0.05, we reject the null hypothesis and conclude that there is a relationship between median household income and per capita traffic fines revenue.
Estimate bootstrap confidence intervals for the slope
Demo: Estimate the 95% confidence interval for the slope of the relationship between median household income and per capita traffic fines revenue.
# bootstrap distribution for CIs
boot_full_dist <- traffic_fines |>
specify(vehicle_code_fines_i_p ~ med_inc) |>
generate(reps = 1000, type = "bootstrap") |>
fit()
# get 95% confidence interval
conf_ints <- get_ci(boot_full_dist, level = 0.95, point_estimate = obs_fit)
visualize(boot_full_dist) +
shade_confidence_interval(conf_ints)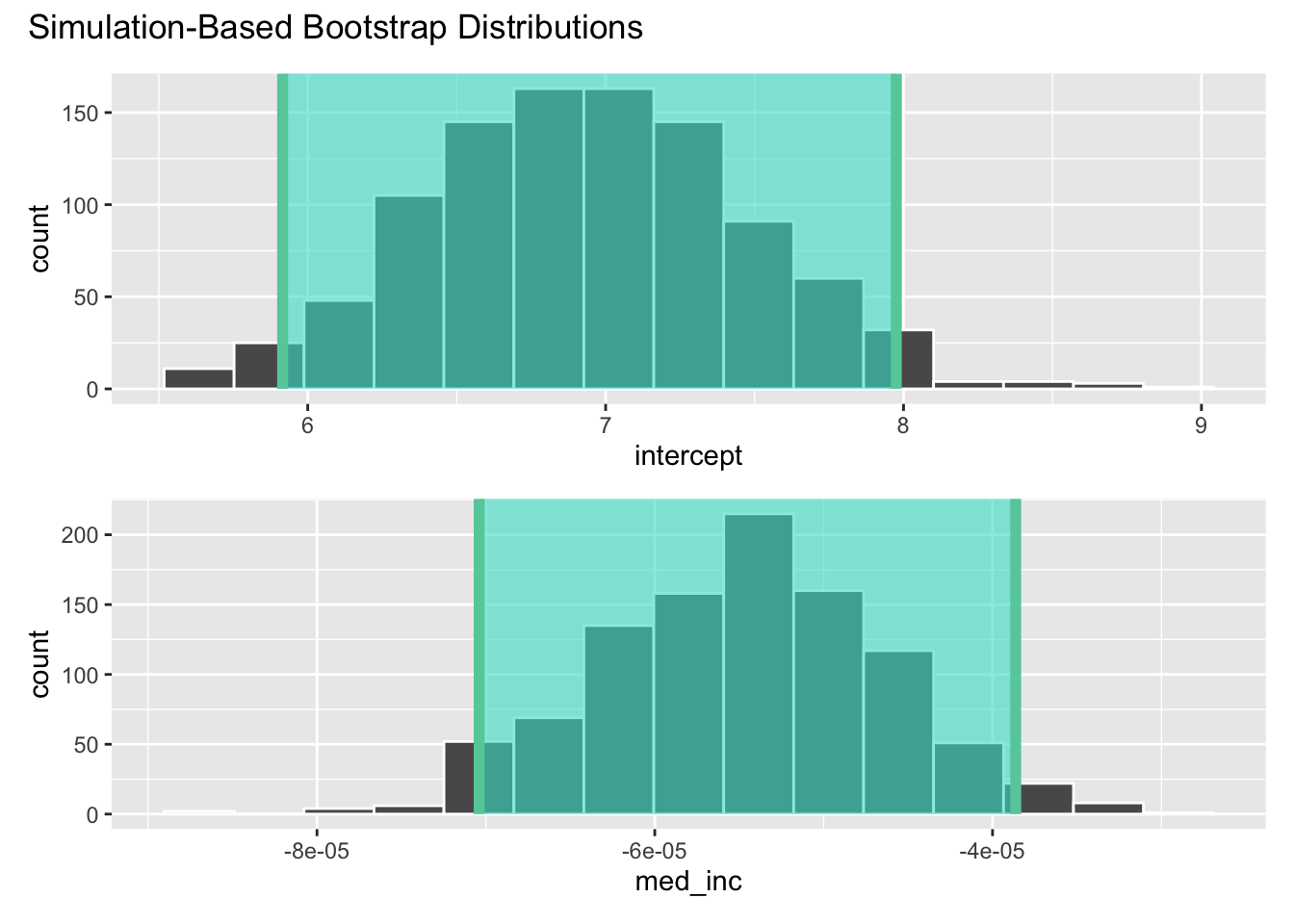
Your turn: How do we interpret this confidence interval?
Add response here. We are 95% confident that the true slope of the relationship between median household income and per capita traffic fines revenue is between -$0.0000704 and -$0.0000386.
Another model with a categorical explanatory variable
Your turn: Now let us ask the question we most care about: do politicians manipulate government policy during electoral years in an effort to gain an electoral advantage? In order to answer the question, we will examine the relationship between whether or not a sheriff election is held in the year and per capita traffic fines revenue.
Response variable:
vehicle_code_fines_i_pPredictor variable:
elec_dummyPredictor type: Categorical
Demo: Make an appropriate visualization to investigate this relationship below. Additionally, calculate the mean per capita traffic fines revenue for years that are and are not election years.
ggplot(
data = traffic_fines,
mapping = aes(x = elec_dummy, y = vehicle_code_fines_i_p)
) +
geom_boxplot()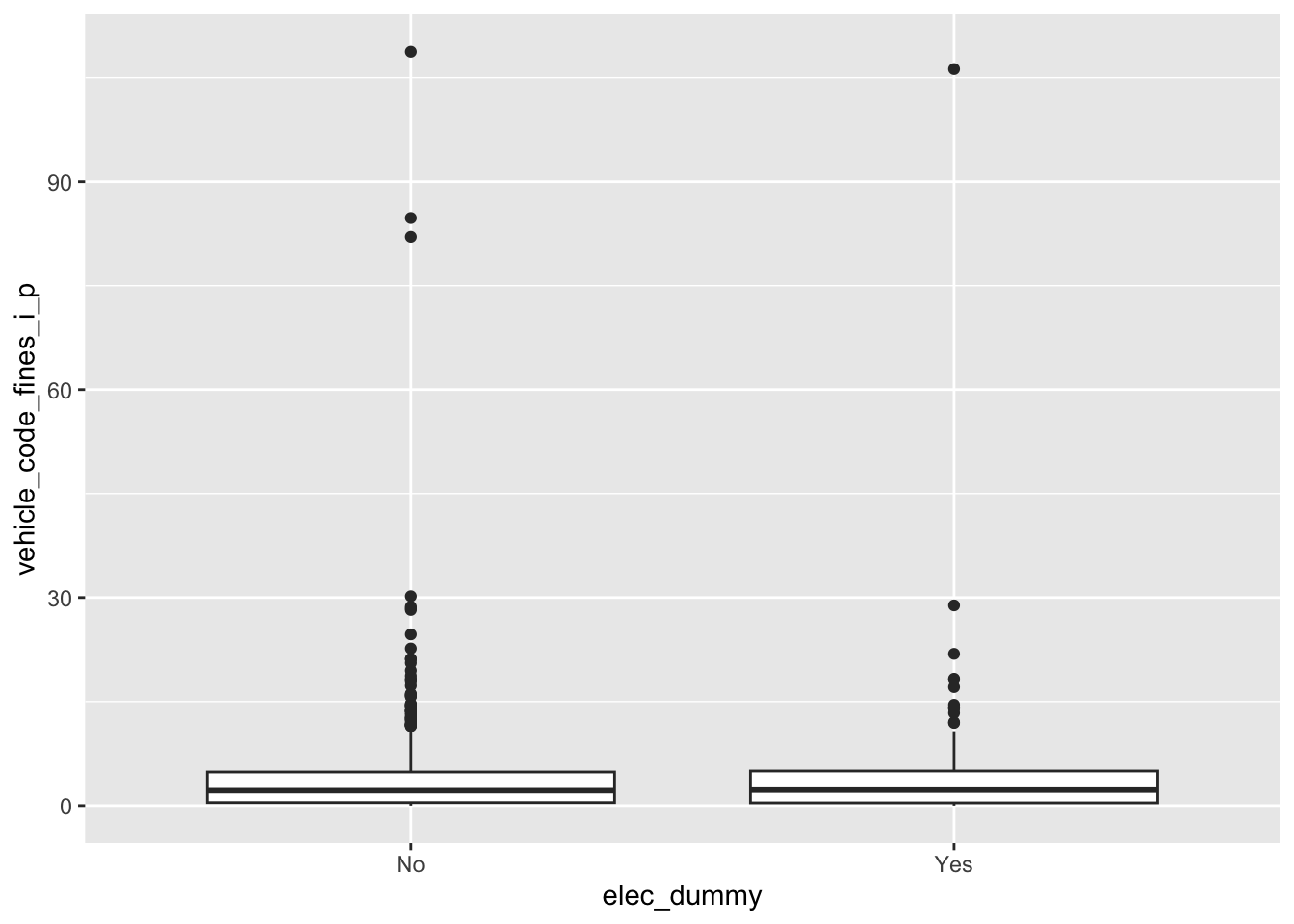
# A tibble: 2 × 2
elec_dummy mean_fines
<chr> <dbl>
1 No 3.90
2 Yes 3.91Demo: Change the geom of your previous plot to geom_point(). Use this plot to think about how R models these data.
ggplot(
data = traffic_fines,
mapping = aes(x = elec_dummy, y = vehicle_code_fines_i_p)
) +
geom_point()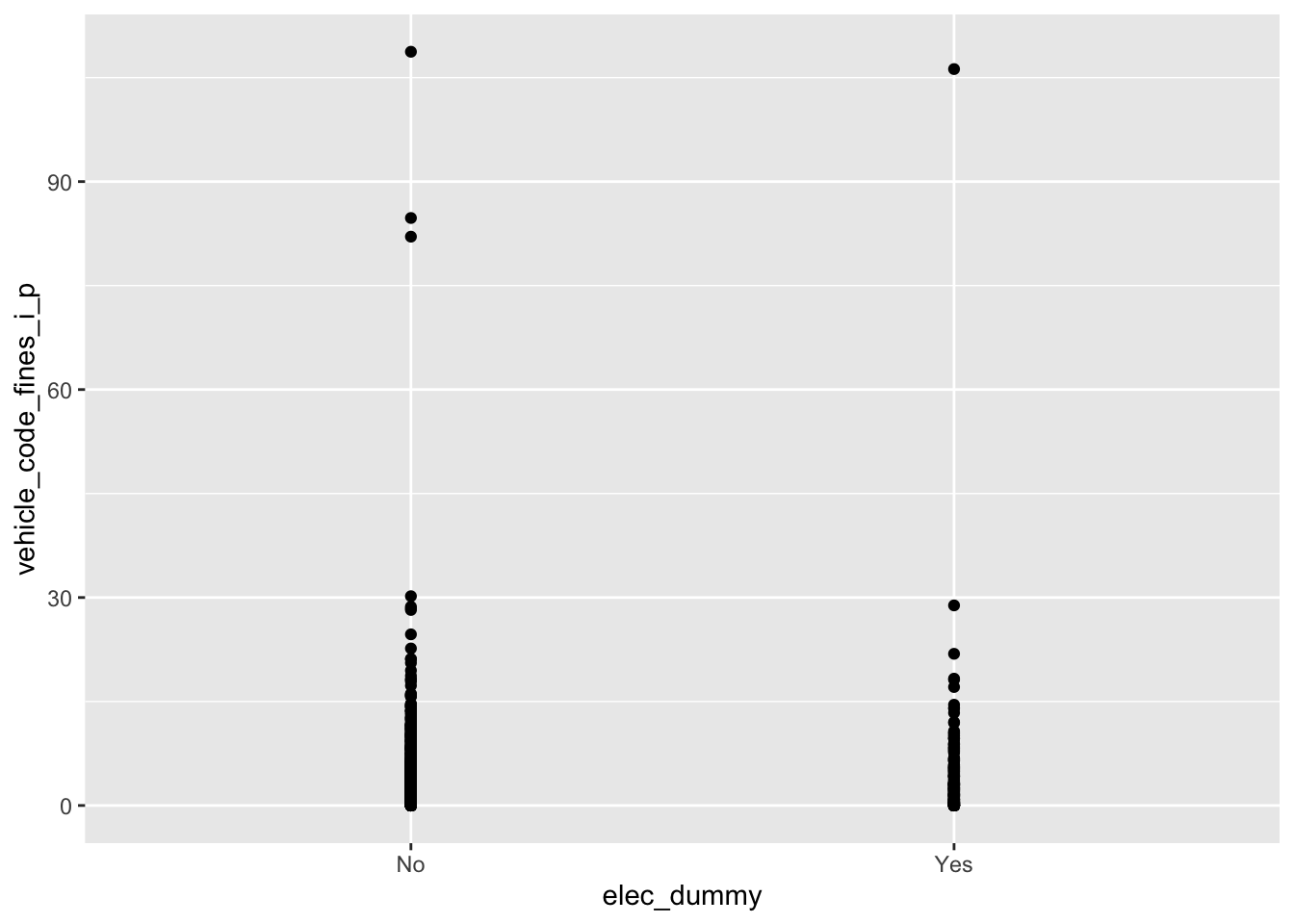
Your turn: Fit the linear regression model and display the results. Print the estimated model output below.
fines_elec_dummy_fit <- linear_reg() |>
fit(vehicle_code_fines_i_p ~ elec_dummy, data = traffic_fines)
tidy(fines_elec_dummy_fit)# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3.90 0.256 15.2 2.84e-47
2 elec_dummyYes 0.0171 0.543 0.0315 9.75e- 1Demo: Interpret the slope and the intercept in the context of the data.
Intercept: Counties not in an election year are expected to earn, on average, $3.90 per capita in traffic fines revenue.
Slope: Counties in an election year are expected to earn, on average, $0.02 less per capita in traffic fines revenue than those not in an election year.
Conduct a hypothesis test
Your turn: State the hypotheses to evaluate the relationship between median household income and per capita traffic fines revenue.
-
Null hypothesis: There is no linear relationship between whether or not it is an election year and per capita traffic fines revenue.
\[H_0: \beta_1 = 0\]
-
Alternative hypothesis: There is some linear relationship between whether or not it is an election year and per capita traffic fines revenue.
\[H_A: \beta_1 \neq 0\]
Demo: Use permutation-based methods to conduct the hypothesis test.
# calculate observed fit
obs_fit <- traffic_fines |>
specify(vehicle_code_fines_i_p ~ elec_dummy) |>
fit()
# generate permuted null distribution
null_dist <- traffic_fines |>
specify(vehicle_code_fines_i_p ~ elec_dummy) |>
hypothesize(null = "independence") |>
generate(reps = 1000, type = "permute") |>
fit()
# visualize and calculate p-value
visualize(null_dist) +
shade_p_value(obs_fit, direction = "both")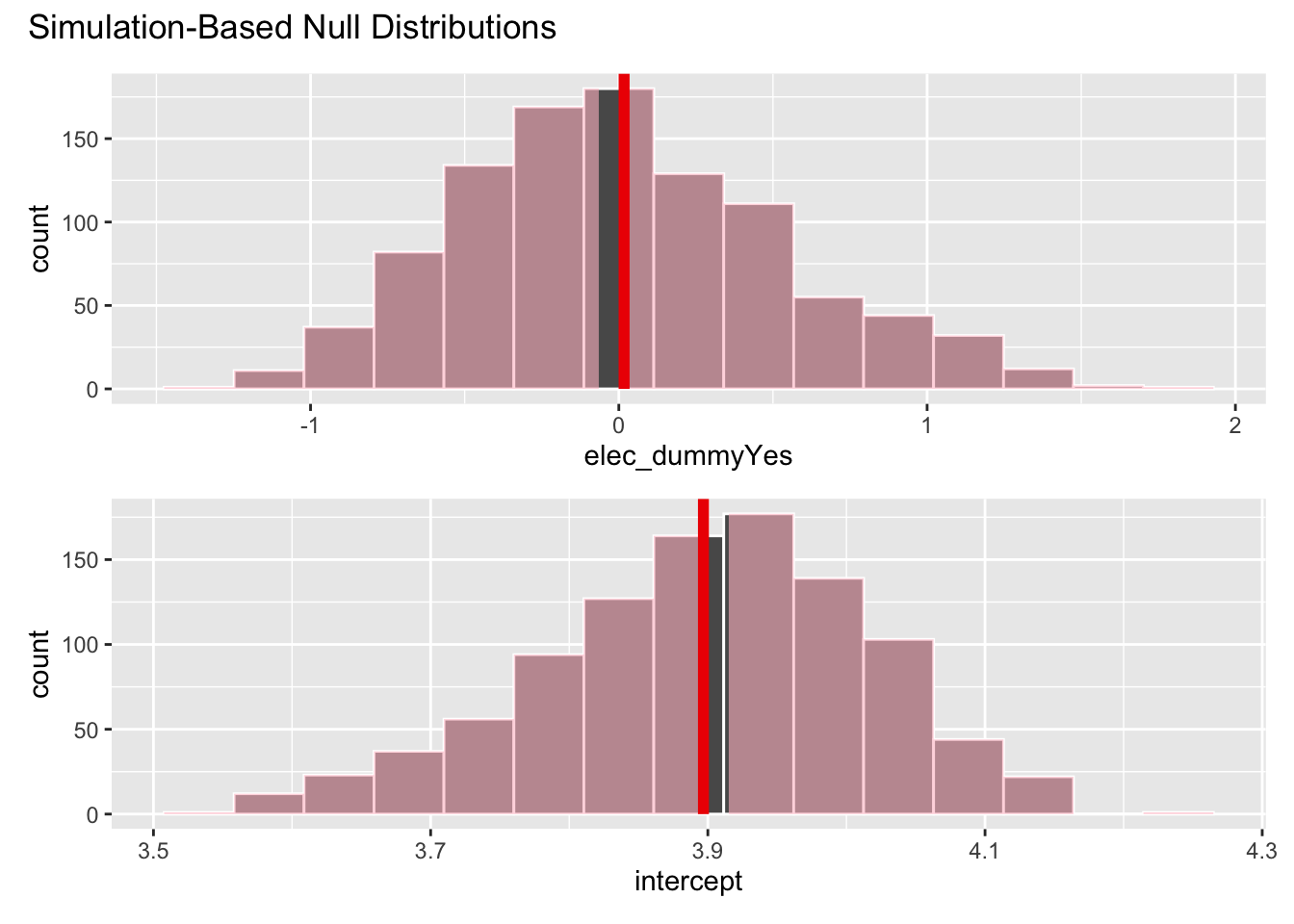
get_p_value(null_dist, obs_fit, direction = "both")# A tibble: 2 × 2
term p_value
<chr> <dbl>
1 elec_dummyYes 0.942
2 intercept 0.942Your turn: Interpret the \(p\)-value in context of the data and the research question. Use a significance level of 5%.
Add response here. If in fact the true relationship between whether or not it is an election and per capita traffic fines revenue is zero, the probability of observing a relationship as strong as the one in the data is less than 0.95. Since this is greater than 0.05, we fail to reject the null hypothesis and cannot conclude that there is a relationship between whether or not it is an election and per capita traffic fines revenue.
Check model conditions
Recall the technical conditions for linear regression:
- L: linear model
- I: independent observations
- N: points are normally distributed around the line
- E: equal variability around the line for all values of the explanatory variable
Your turn: Check the linearity assumption for the model with elec_dummy as the predictor. Examine the residuals to assist you with this process.
# augment() allows us to extract observation-level statistics from a model object
fines_elec_dummy_aug <- augment(fines_elec_dummy_fit, new_data = traffic_fines)
fines_elec_dummy_aug# A tibble: 1,025 × 8
.pred .resid year county_code county_name vehicle_code_fines_i_p med_inc
<dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
1 3.90 -0.507 2003 1 Alameda 3.39 56225
2 3.90 -0.107 2004 1 Alameda 3.79 57659
3 3.90 -0.899 2005 1 Alameda 3.00 60937
4 3.91 -0.639 2006 1 Alameda 3.27 64285
5 3.90 -0.591 2007 1 Alameda 3.31 68263
6 3.90 -0.388 2008 1 Alameda 3.51 70217
7 3.90 -0.276 2009 1 Alameda 3.62 68258
8 3.91 -0.713 2010 1 Alameda 3.20 66937
9 3.90 -1.15 2011 1 Alameda 2.75 67295
10 3.90 -1.63 2012 1 Alameda 2.27 70209
# ℹ 1,015 more rows
# ℹ 1 more variable: elec_dummy <chr># the linear regression model
ggplot(
data = fines_elec_dummy_aug,
mapping = aes(
x = as.numeric(elec_dummy == "Yes"),
y = vehicle_code_fines_i_p
)
) +
geom_point() +
geom_smooth(method = "lm")`geom_smooth()` using formula = 'y ~ x'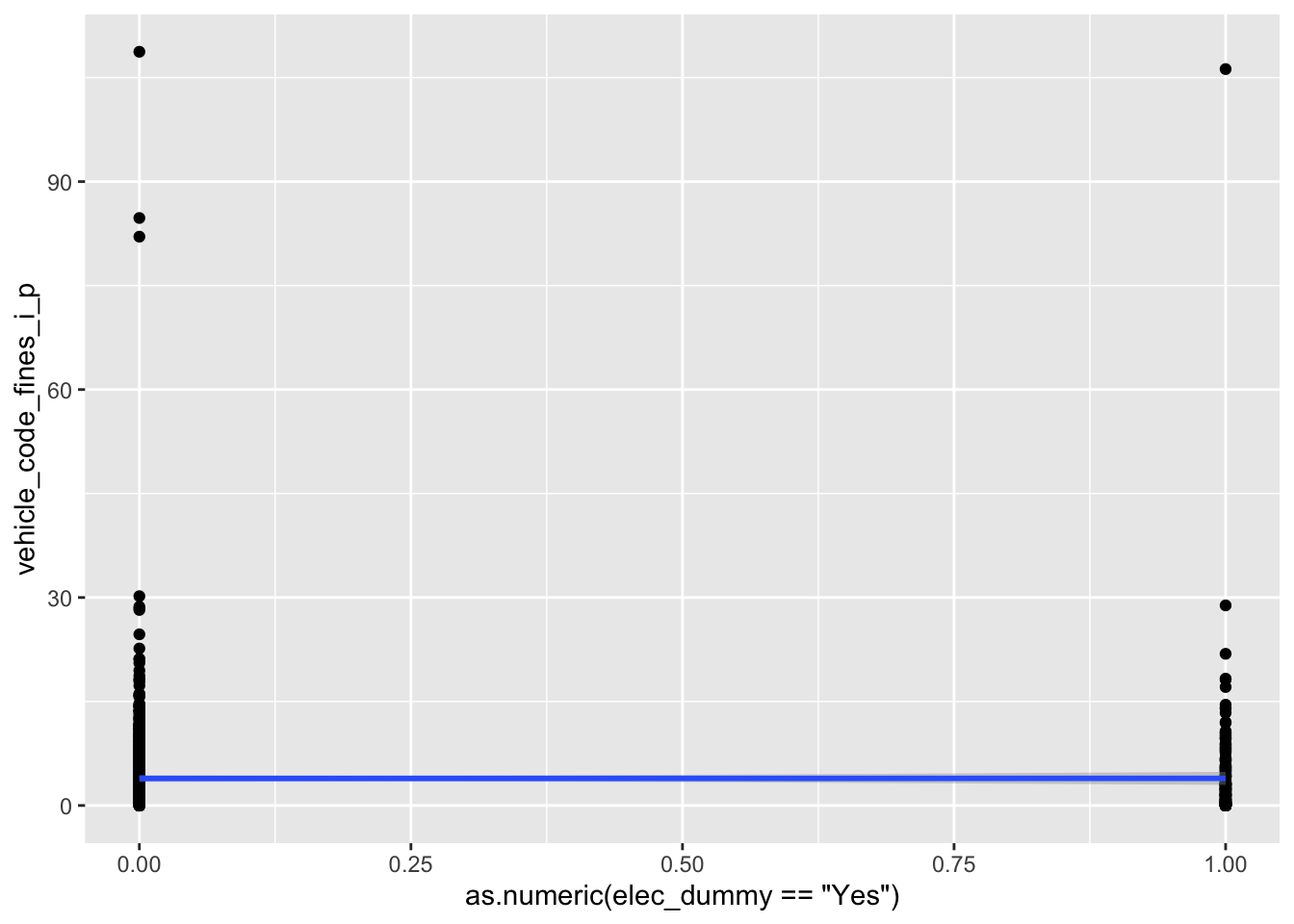
# distribution of the residuals
ggplot(data = fines_elec_dummy_aug, mapping = aes(x = .resid)) +
geom_histogram()`stat_bin()` using `bins = 30`. Pick better value `binwidth`.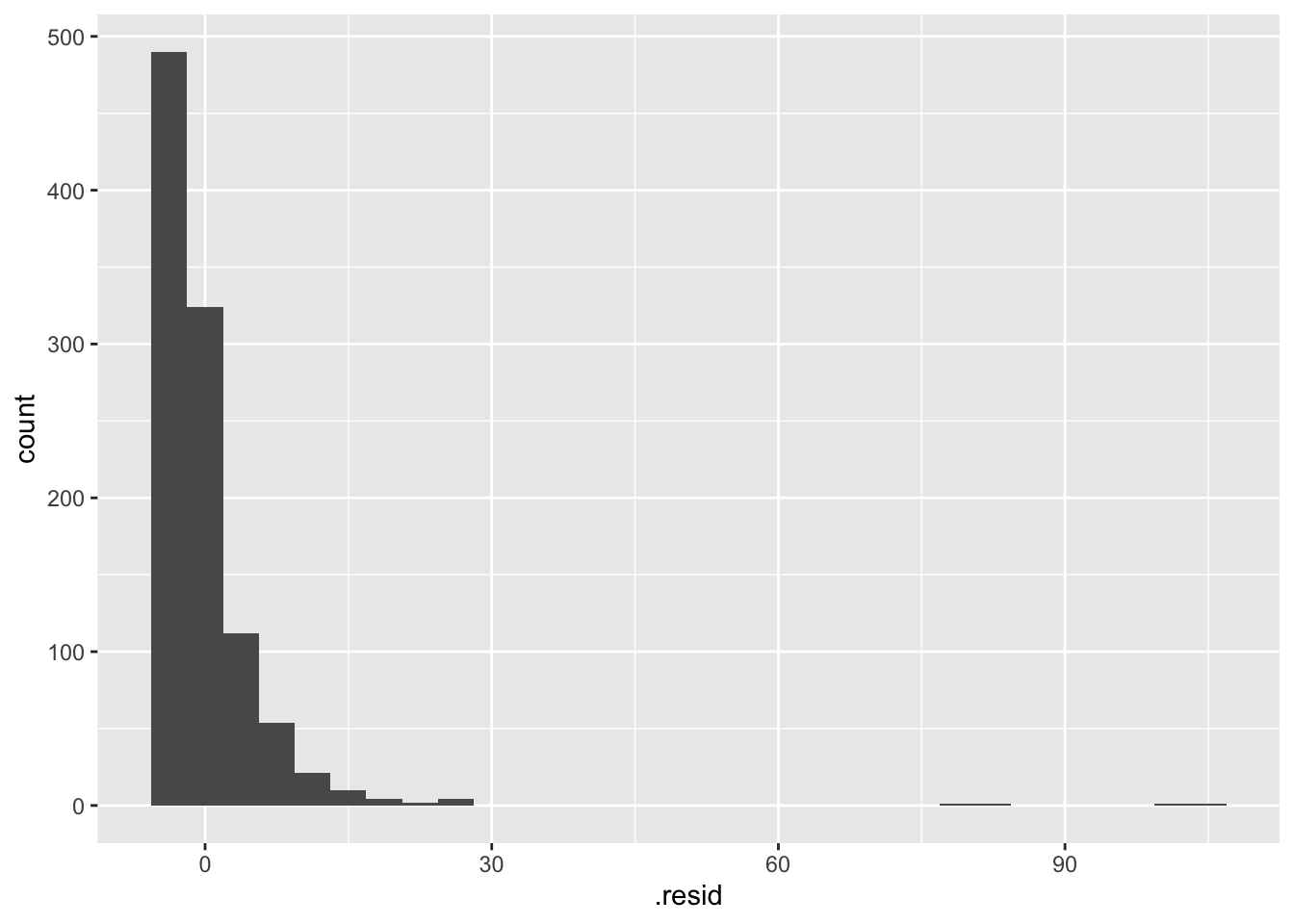
# use the .resid column to plot the predicted values vs. the residuals
# jitter because the explanatory variable only has 2 unique values
ggplot(data = fines_elec_dummy_aug, mapping = aes(x = .pred, y = .resid)) +
geom_jitter() +
geom_hline(yintercept = 0, linetype = "dashed")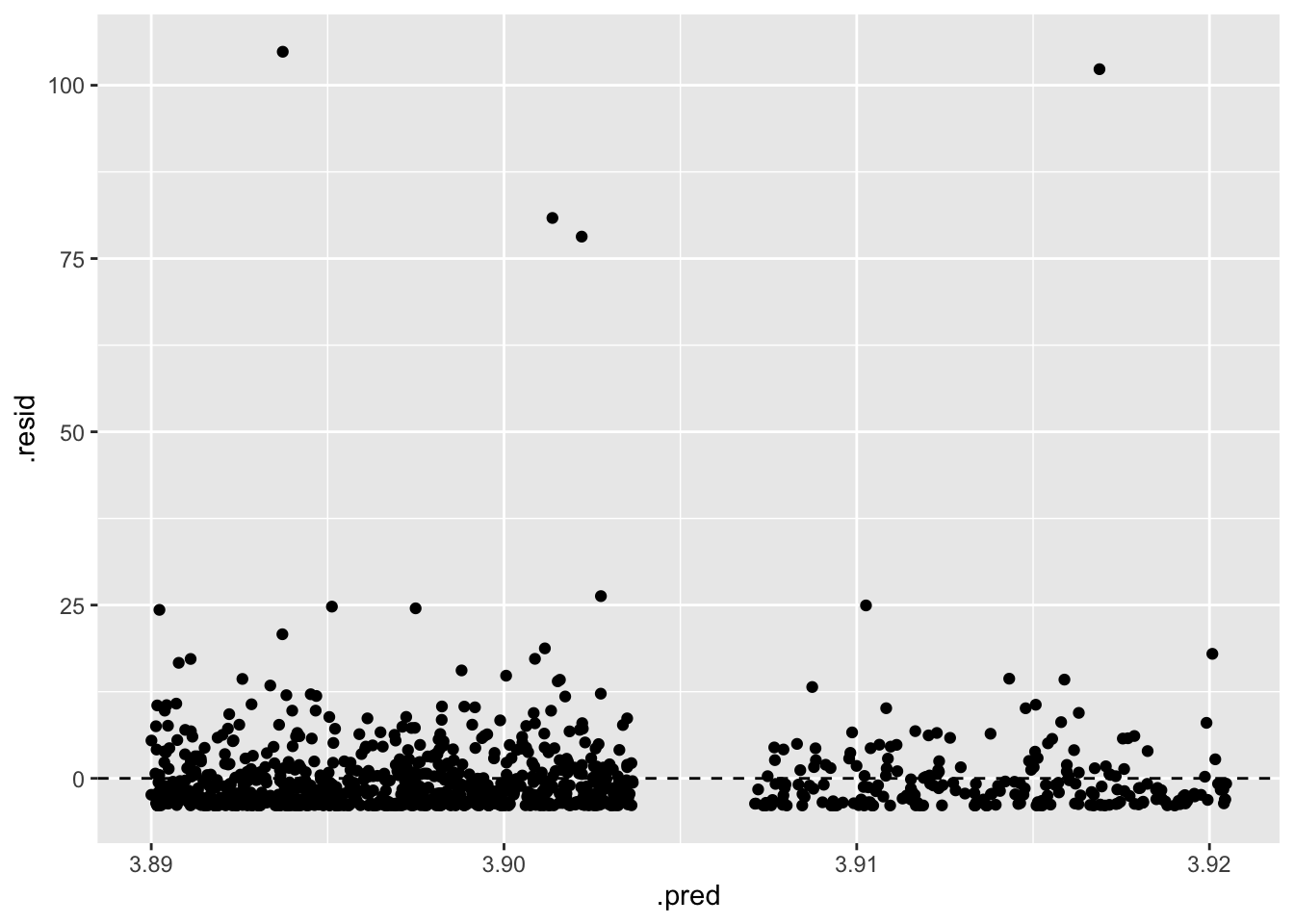
-
L: linear model - Add response here.
Doesn’t seem very linear in the relationship. The fact that we have a categorical variable as the predictor is not inherently a problem, but it doesn’t seem like there is a straight, monotonic relationship between the predictor and the response.
-
I: independent observations - Add response here.
Absolutely no. There are many reasons why the observations are not independent. The obvious reason is that it is a time series cross-sectional (TSCS) panel structure. Each county is observed over multiple years, and the observations within a county are likely to be correlated. Alternatively, each year is observed over multiple counties, and the observations within a year are likely to be correlated.
-
N: points are normally distributed around the line - Add response here.
No. The boxplot earlier shows there are many outliers in the data. The residuals are not normally distributed around the line.
-
E: equal variability around the line for all values of the explanatory variable - Add response here.
No. The residuals are not equally variable around the line for all values of the explanatory variable. The residuals are more variable for counties in an election year than for counties not in an election year.
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.5.2 (2025-10-31)
os macOS Tahoe 26.3.1
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/New_York
date 2026-03-25
pandoc 3.4 @ /usr/local/bin/ (via rmarkdown)
quarto 1.9.36 @ /usr/local/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
! package * version date (UTC) lib source
P archive 1.1.12.1 2025-12-24 [?] RSPM
P backports 1.5.0 2024-05-23 [?] RSPM (R 4.5.0)
P base64enc 0.1-3 2015-07-28 [?] RSPM (R 4.5.0)
P bit 4.6.0 2025-03-06 [?] RSPM (R 4.5.0)
P bit64 4.6.0-1 2025-01-16 [?] RSPM (R 4.5.0)
P broom * 1.0.11 2025-12-04 [?] RSPM (R 4.5.0)
P class 7.3-23 2025-01-01 [?] RSPM (R 4.5.0)
P cli 3.6.5 2025-04-23 [?] RSPM (R 4.5.0)
P codetools 0.2-20 2024-03-31 [?] RSPM (R 4.5.0)
P crayon 1.5.3 2024-06-20 [?] RSPM (R 4.5.0)
P data.table 1.18.0 2025-12-24 [?] RSPM (R 4.5.0)
P dials * 1.4.2 2025-09-04 [?] RSPM
P DiceDesign 1.10 2023-12-07 [?] RSPM (R 4.5.0)
P digest 0.6.39 2025-11-19 [?] RSPM (R 4.5.0)
P dplyr * 1.2.0 2026-02-03 [?] RSPM
P evaluate 1.0.5 2025-08-27 [?] RSPM (R 4.5.0)
P farver 2.1.2 2024-05-13 [?] RSPM (R 4.5.0)
P fastmap 1.2.0 2024-05-15 [?] RSPM (R 4.5.0)
P forcats * 1.0.1 2025-09-25 [?] RSPM (R 4.5.0)
P furrr 0.3.1 2022-08-15 [?] RSPM
P future 1.68.0 2025-11-17 [?] RSPM
P future.apply 1.20.1 2025-12-09 [?] CRAN (R 4.5.2)
P generics 0.1.4 2025-05-09 [?] RSPM (R 4.5.0)
P ggplot2 * 4.0.1 2025-11-14 [?] RSPM (R 4.5.0)
P globals 0.18.0 2025-05-08 [?] RSPM
P glue 1.8.0 2024-09-30 [?] RSPM (R 4.5.0)
P gower 1.0.2 2024-12-17 [?] RSPM
P GPfit 1.0-9 2025-04-12 [?] RSPM (R 4.5.0)
P gtable 0.3.6 2024-10-25 [?] RSPM (R 4.5.0)
P hardhat 1.4.2 2025-08-20 [?] RSPM
P here 1.0.2 2025-09-15 [?] CRAN (R 4.5.0)
P hms 1.1.4 2025-10-17 [?] RSPM (R 4.5.0)
P htmltools 0.5.9 2025-12-04 [?] RSPM (R 4.5.0)
P htmlwidgets 1.6.4 2023-12-06 [?] RSPM (R 4.5.0)
P infer * 1.1.0 2025-12-18 [?] CRAN (R 4.5.2)
P ipred 0.9-15 2024-07-18 [?] RSPM
P jsonlite 2.0.0 2025-03-27 [?] RSPM (R 4.5.0)
P knitr 1.51 2025-12-20 [?] RSPM (R 4.5.0)
P labeling 0.4.3 2023-08-29 [?] RSPM (R 4.5.0)
P lattice 0.22-7 2025-04-02 [?] RSPM (R 4.5.0)
P lava 1.8.2 2025-10-30 [?] RSPM
P lhs 1.2.0 2024-06-30 [?] RSPM (R 4.5.0)
P lifecycle 1.0.5 2026-01-08 [?] RSPM (R 4.5.0)
P listenv 0.10.0 2025-11-02 [?] RSPM
P lubridate * 1.9.4 2024-12-08 [?] RSPM (R 4.5.0)
P magrittr 2.0.4 2025-09-12 [?] RSPM (R 4.5.0)
P MASS 7.3-65 2025-02-28 [?] RSPM (R 4.5.0)
P Matrix 1.7-4 2025-08-28 [?] RSPM (R 4.5.0)
P mgcv 1.9-4 2025-11-07 [?] CRAN (R 4.5.0)
P modeldata * 1.5.1 2025-08-22 [?] RSPM
P nlme 3.1-168 2025-03-31 [?] RSPM (R 4.5.0)
P nnet 7.3-20 2025-01-01 [?] RSPM (R 4.5.0)
P otel 0.2.0 2025-08-29 [?] RSPM (R 4.5.0)
P parallelly 1.46.0 2025-12-12 [?] CRAN (R 4.5.2)
P parsnip * 1.4.0 2025-12-01 [?] CRAN (R 4.5.2)
P patchwork 1.3.2 2025-08-25 [?] RSPM
P pillar 1.11.1 2025-09-17 [?] RSPM (R 4.5.0)
P pkgconfig 2.0.3 2019-09-22 [?] RSPM (R 4.5.0)
P prodlim 2025.04.28 2025-04-28 [?] RSPM
P purrr * 1.2.0 2025-11-04 [?] CRAN (R 4.5.0)
P R6 2.6.1 2025-02-15 [?] RSPM (R 4.5.0)
P RColorBrewer 1.1-3 2022-04-03 [?] RSPM (R 4.5.0)
P Rcpp 1.1.0 2025-07-02 [?] RSPM (R 4.5.0)
P readr * 2.1.6 2025-11-14 [?] RSPM (R 4.5.0)
P recipes * 1.3.1 2025-05-21 [?] RSPM
renv 1.1.5 2025-07-24 [1] RSPM (R 4.5.0)
P repr 1.1.7 2024-03-22 [?] RSPM
P rlang 1.1.7 2026-01-09 [?] RSPM (R 4.5.0)
P rmarkdown 2.30 2025-09-28 [?] RSPM (R 4.5.0)
P rpart 4.1.24 2025-01-07 [?] RSPM (R 4.5.0)
P rprojroot 2.1.1 2025-08-26 [?] RSPM (R 4.5.0)
P rsample * 1.3.1 2025-07-29 [?] RSPM
P rstudioapi 0.17.1 2024-10-22 [?] RSPM (R 4.5.0)
P S7 0.2.1 2025-11-14 [?] RSPM (R 4.5.0)
P scales * 1.4.0 2025-04-24 [?] RSPM (R 4.5.0)
P sessioninfo 1.2.3 2025-02-05 [?] RSPM (R 4.5.0)
P skimr * 2.2.1 2025-07-26 [?] RSPM
P sparsevctrs 0.3.5 2025-12-09 [?] CRAN (R 4.5.2)
P stringi 1.8.7 2025-03-27 [?] RSPM (R 4.5.0)
P stringr * 1.6.0 2025-11-04 [?] RSPM (R 4.5.0)
P survival 3.8-3 2024-12-17 [?] RSPM (R 4.5.0)
P tailor * 0.1.0 2025-08-25 [?] RSPM
P tibble * 3.3.0 2025-06-08 [?] RSPM (R 4.5.0)
P tidymodels * 1.4.1 2025-09-08 [?] RSPM
P tidyr * 1.3.2 2025-12-19 [?] RSPM (R 4.5.0)
P tidyselect 1.2.1 2024-03-11 [?] RSPM (R 4.5.0)
P tidyverse * 2.0.0 2023-02-22 [?] RSPM (R 4.5.0)
P timechange 0.3.0 2024-01-18 [?] RSPM (R 4.5.0)
P timeDate 4051.111 2025-10-17 [?] RSPM
P tune * 2.0.1 2025-10-17 [?] RSPM
P tzdb 0.5.0 2025-03-15 [?] RSPM (R 4.5.0)
P utf8 1.2.6 2025-06-08 [?] RSPM (R 4.5.0)
P vctrs 0.7.1 2026-01-23 [?] RSPM
P vroom 1.6.7 2025-11-28 [?] RSPM (R 4.5.0)
P withr 3.0.2 2024-10-28 [?] RSPM (R 4.5.0)
P workflows * 1.3.0 2025-08-27 [?] RSPM
P workflowsets * 1.1.1 2025-05-27 [?] RSPM
P xfun 0.55 2025-12-16 [?] CRAN (R 4.5.2)
P yaml 2.3.12 2025-12-10 [?] RSPM (R 4.5.0)
P yardstick * 1.3.2 2025-01-22 [?] RSPM
[1] /Users/bcs88/Projects/info-2950/course-site/renv/library/macos/R-4.5/aarch64-apple-darwin20
[2] /Users/bcs88/Library/Caches/org.R-project.R/R/renv/sandbox/macos/R-4.5/aarch64-apple-darwin20/4cd76b74
* ── Packages attached to the search path.
P ── Loaded and on-disk path mismatch.
──────────────────────────────────────────────────────────────────────────────Footnotes
Su, Min, and Christian Buerger. 2025. “Playing politics with traffic fines: Sheriff elections and political cycles in traffic fines revenue.” American Journal of Political Science 69: 164–175. https://doi.org/10.1111/ajps.12866↩︎
The codebook is available from Dataverse. The data set has been lightly cleaned for the application exercise.↩︎