Rows: 5,926
Columns: 15
$ label <fct> Ham, Ham, Ham, Ham, Spam, Spam, Ham, …
$ url <chr> "No", "No", "No", "No", "No", "Yes", …
$ email <chr> "No", "No", "No", "No", "No", "No", "…
$ phone <chr> "No", "No", "No", "No", "No", "Yes", …
$ char_count <int> 136, 79, 28, 173, 152, 76, 93, 132, 1…
$ word_count <int> 26, 17, 5, 33, 24, 7, 18, 30, 30, 5, …
$ avg_word_length <dbl> 5.230769, 4.647059, 5.600000, 5.24242…
$ exclamation_count <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ uppercase_ratio <dbl> 0.08088235, 0.03797468, 0.03571429, 0…
$ has_urgency_word <fct> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ has_money_keyword <fct> 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0…
$ has_action_cta <fct> 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ has_org_name <fct> 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0…
$ digit_count <int> 9, 0, 0, 0, 5, 6, 0, 3, 2, 0, 0, 0, 0…
$ has_shortlink <fct> 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0…Models for discrete outcomes
Lecture 20
Dr. Benjamin Soltoff
Cornell University
INFO 2951 - Spring 2026
April 7, 2026
Announcements
Announcements
- Quiz 02 regrade requests due end of week
- Project EDA feedback
- Preregistration of analyses due next week
Learning objectives
- Fit and interpret models for predicting binary outcomes
- Evaluate the performance of these models
- Determine appropriate decision thresholds
- Implement train/test set splits for model validation
Predicting categorical data
Spam filters
- Data from 5926 text messages and 15 variables on them
- Outcome: whether the message is Ham or Spam
- Predictors:
- Number of characters
- Whether the message contained a URL
- Number of times common organizations were mentioned (e.g. “Amazon”, “IRS”, “Bank”)
- Etc.
Would you expect longer or shorter messages to be spam?
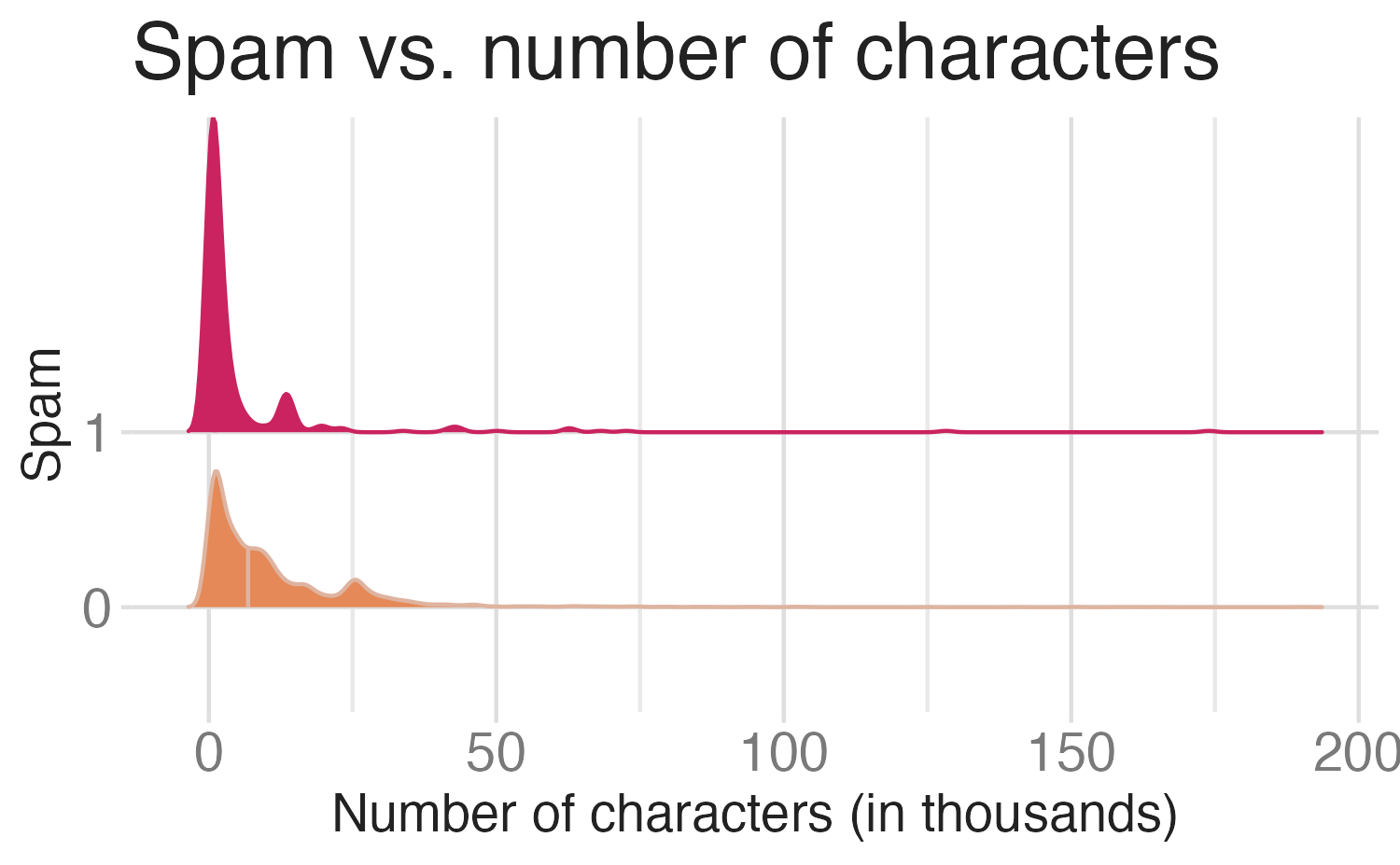
# A tibble: 2 × 2
label mean_char_count
<fct> <dbl>
1 Spam 137.
2 Ham 70.7Would you expect messages that contain a URL to be spam or not?
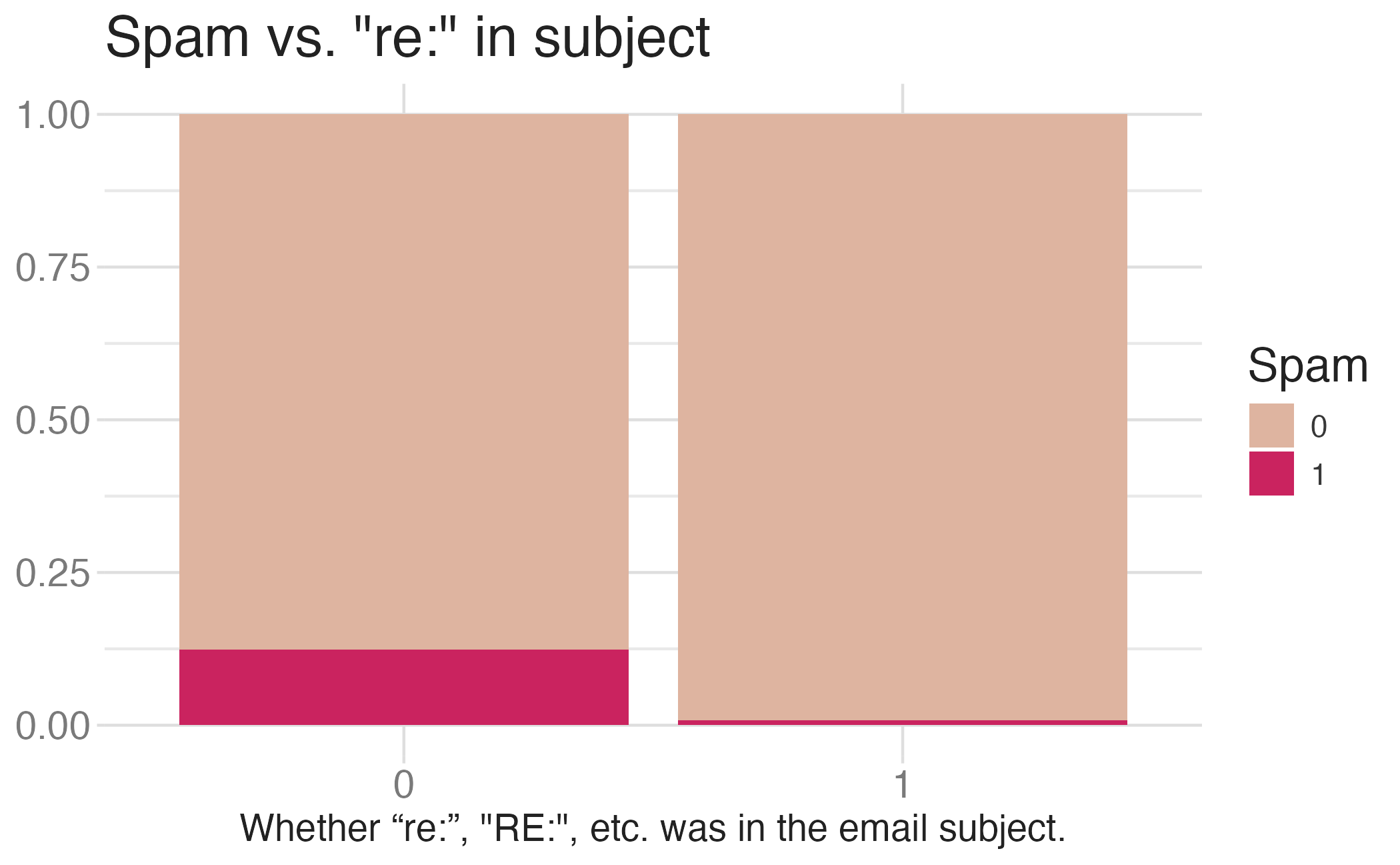
Modeling spam
- Both number of characters and whether the message has a URL might be related to whether the message is spam. How do we come up with a model that will let us explore this relationship?
- For simplicity, we’ll focus on the number of characters (
char_count) as predictor, but the model we describe can be expanded to take multiple predictors as well.
Modeling spam
This isn’t something we can reasonably fit a linear model to – we need something different!
Feel the Bern(oulli)

Framing the problem
We can treat each outcome (spam and not) as successes and failures arising from separate Bernoulli trials
- Bernoulli trial: a random experiment with exactly two possible outcomes, “success” and “failure”, in which the probability of success is the same every time the experiment is conducted
Each Bernoulli trial can have a separate probability of success
\[ y_i ∼ \text{Bern}(p_i)\]
We can then use the predictor variables to model that probability of success, \(p_i\)
We can’t just use a linear model for \(p_i\) (since \(p_i\) must be between 0 and 1) but we can transform the linear model to have the appropriate range
Generalized linear models
- This is a very general way of addressing many problems in regression and the resulting models are called generalized linear models (GLMs)
- Logistic regression is just one example
- Binary outcomes
- Ordinal outcomes
- Nominal outcomes
- Event counts
- Survival/duration models
- Continuous outcomes
Three characteristics of GLMs
A probability distribution describing a data generating process for the outcome variable
A linear model \[\eta = \beta_0 + \beta_1 X_1 + \cdots + \beta_k X_k\]
A link function that relates the linear model to the parameter of the outcome distribution
Logistic regression
Logistic regression
Logistic regression is a GLM used to model a binary categorical outcome using numerical and categorical predictors
To finish specifying the logistic model we need to define a reasonable link function that connects \(\eta_i\) to \(p_i\)
Logit function: For \(0\le p \le 1\)
\[\text{logit}(p) = \log\left(\frac{p}{1-p}\right)\]
Logit function, visualized

Properties of the logit
The logit function takes a value between 0 and 1 and maps it to a value between \(-\infty\) and \(\infty\)
Inverse logit (logistic) function:
\[g^{-1}(x) = \frac{\exp(x)}{1+\exp(x)} = \frac{1}{1+\exp(-x)}\]
The inverse logit function takes a value between \(-\infty\) and \(\infty\) and maps it to a value between 0 and 1
The logistic regression model
- Based on the three GLM criteria we have
- \(y_i \sim \text{Bern}(p_i)\)
- \(\eta_i = \beta_0+\beta_1 x_{1,i} + \cdots + \beta_n x_{n,i}\)
- \(\text{logit}(p_i) = \eta_i\)
- From which we get
\[p_i = \frac{\exp(\beta_0+\beta_1 x_{1,i} + \cdots + \beta_k x_{k,i})}{1+\exp(\beta_0+\beta_1 x_{1,i} + \cdots + \beta_k x_{k,i})}\]
Modeling spam
In R we fit a GLM in the same way as a linear model except we specify the model with logistic_reg()
Spam model
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -3.64 0.0935 -38.9 0
2 char_count 0.0217 0.000770 28.1 5.48e-174Model:
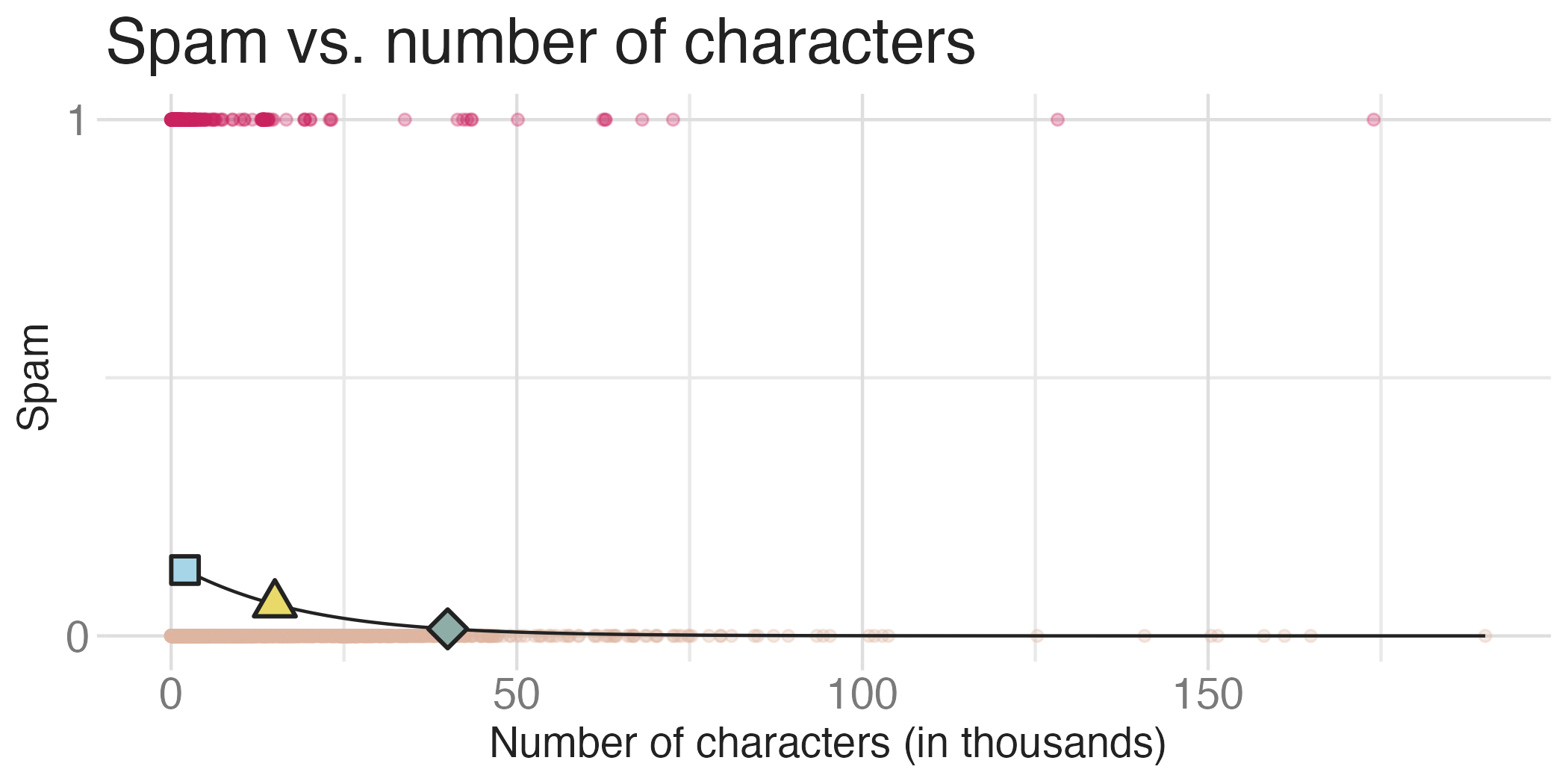
\[\log\left(\frac{p}{1-p}\right) = −3\\.64 + 0\\.02 \times \text{char\_count}\]
\(\Pr(\text{spam})\) for a message with 200 characters
\[\log\left(\frac{p}{1-p}\right) = −3\\.64 + 0\\.02 \times 200 = 0\\.69\]
\[\frac{p}{1-p} = \exp(0\\.69) = 2\\.00 \rightarrow p = 2\\.00 \times (1 - p)\]
\[p = 2\\.00 - 2\\.00 p \rightarrow 3 p = 2\]
\[p = 2 / 3 \approx 0.67\]
What is the probability that a message with 100 characters is spam? What about a message with 400 characters?

- \(100 \, \text{chars}: \Pr (\text{spam}) = 0.19\)
- \(200 \, \text{chars}: \Pr (\text{spam}) = 0.67\)
- \(400 \, \text{chars}: \Pr (\text{spam}) = 0.99\)
Would you prefer a message with 200 characters to be labeled as spam or not? How about 400 characters?
Sensitivity and specificity
False positive and negative
| Message is spam | Message is not spam | |
|---|---|---|
| Message labeled spam | True positive | False positive (Type 1 error) |
| Message labeled not spam | False negative (Type 2 error) | True negative |
- False negative rate = Pr(Labeled not spam | Message spam) = FN / (TP + FN)
- False positive rate = Pr(Labeled spam | Message not spam) = FP / (FP + TN)
Sensitivity and specificity
| Message is spam | Message is not spam | |
|---|---|---|
| Message labeled spam | True positive | False positive (Type 1 error) |
| Message labeled not spam | False negative (Type 2 error) | True negative |
- Sensitivity = Pr(Labeled spam | Message spam) = TP / (TP + FN)
- Sensitivity = 1 − False negative rate
- Probability that the model identifies spam given that the message is spam
- Specificity = Pr(Labeled not spam | Message not spam) = TN / (FP + TN)
- Specificity = 1 − False positive rate
- Probability that the model identifies not spam given that the message is not spam
If you were designing a spam filter, would you want sensitivity and specificity to be high or low? What are the trade-offs associated with each decision?
- Sensitivity - probability that the model identifies spam given that the message is spam
- Specificity - probability that the model identifies not spam given that the message is not spam
Prediction
Goal: Building a spam filter
- Data: Set of messages and we know if each message is spam/not and other features
- Use logistic regression to predict the probability that an incoming message is spam
- Use model selection to pick the model with the best predictive performance
- Building a model to predict the probability that a message is spam is only half of the battle! We also need a decision rule about which messages get flagged as spam (e.g. what probability should we use as our cutoff?)
- A simple approach: choose a single threshold probability and any message that exceeds that probability is flagged as spam
A multiple regression approach
# A tibble: 15 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -5.37 0.364 -14.8 1.94e-49
2 urlYes 3.93 0.456 8.61 7.15e-18
3 emailYes 4.84 1.27 3.82 1.36e- 4
4 phoneYes 3.16 0.512 6.16 7.11e-10
5 char_count 0.0347 0.00656 5.29 1.23e- 7
6 word_count -0.169 0.0360 -4.70 2.55e- 6
7 avg_word_length 0.0266 0.0513 0.518 6.04e- 1
8 exclamation_count 0.310 0.0909 3.42 6.33e- 4
9 uppercase_ratio 0.904 0.686 1.32 1.88e- 1
10 has_urgency_word1 0.977 0.732 1.33 1.82e- 1
11 has_money_keyword1 2.38 0.223 10.7 1.58e-26
12 has_action_cta1 1.58 0.215 7.34 2.18e-13
13 has_org_name1 0.500 0.482 1.04 2.99e- 1
14 digit_count 0.374 0.0341 11.0 5.31e-28
15 has_shortlink1 2.32 1.32 1.76 7.87e- 2Prediction
- The mechanics of prediction is easy
- Plug in values of predictors to the model equation
- Calculate the predicted value of the response variable, \(\hat{y}\)
- Getting it right is hard!
- There is no guarantee the model estimates you have are correct
- Or that your model will perform as well with new data as it did with your sample data
Underfitting and overfitting
Spending our data
Several steps to create a useful model: parameter estimation, model selection, performance assessment, etc.
Doing all of this on the entire data we have available can lead to overfitting
Allocate specific subsets of data for different tasks, as opposed to allocating the largest possible amount to the model parameter estimation only (which is what we’ve done so far)
Splitting data
Splitting data
- Training set
- Sandbox for model building
- Spend most of your time using the training set to develop the model
- Majority of the data (usually 80%)
- Testing set
- Held in reserve to determine efficacy of one or two chosen models
- Critical to look at it once, otherwise it becomes part of the modeling process
- Remainder of the data (usually 20%)
Performing the split
# Fix random numbers by setting the seed
# Enables analysis to be reproducible when random numbers are used
set.seed(123)
# Put 80% of the data into the training set
spam_split <- initial_split(spam, prop = 0.80)
# Create data frames for the two sets:
train_data <- training(spam_split)
test_data <- testing(spam_split)Peek at the split
Rows: 4,740
Columns: 15
$ label <fct> Ham, Ham, Ham, Ha…
$ url <chr> "No", "No", "No",…
$ email <chr> "No", "No", "No",…
$ phone <chr> "No", "No", "No",…
$ char_count <int> 290, 35, 61, 39, …
$ word_count <int> 59, 6, 10, 9, 28,…
$ avg_word_length <dbl> 4.915254, 5.83333…
$ exclamation_count <int> 0, 0, 0, 0, 1, 0,…
$ uppercase_ratio <dbl> 0.02413793, 0.028…
$ has_urgency_word <fct> 0, 0, 0, 0, 0, 0,…
$ has_money_keyword <fct> 0, 0, 0, 0, 1, 1,…
$ has_action_cta <fct> 0, 0, 0, 0, 1, 1,…
$ has_org_name <fct> 0, 0, 0, 0, 0, 0,…
$ digit_count <int> 0, 0, 0, 0, 8, 12…
$ has_shortlink <fct> 0, 0, 0, 0, 0, 0,…Rows: 1,186
Columns: 15
$ label <fct> Ham, Ham, Ham, Ha…
$ url <chr> "No", "No", "No",…
$ email <chr> "No", "No", "No",…
$ phone <chr> "No", "No", "No",…
$ char_count <int> 173, 133, 31, 32,…
$ word_count <int> 33, 30, 6, 7, 26,…
$ avg_word_length <dbl> 5.242424, 4.43333…
$ exclamation_count <int> 0, 0, 0, 0, 0, 0,…
$ uppercase_ratio <dbl> 0.01734104, 0.030…
$ has_urgency_word <fct> 0, 0, 0, 0, 0, 0,…
$ has_money_keyword <fct> 0, 0, 0, 0, 0, 0,…
$ has_action_cta <fct> 1, 0, 0, 0, 0, 1,…
$ has_org_name <fct> 0, 0, 0, 0, 0, 0,…
$ digit_count <int> 0, 2, 0, 0, 0, 0,…
$ has_shortlink <fct> 0, 0, 0, 0, 0, 0,…Modeling workflow
Fit a model to the training dataset
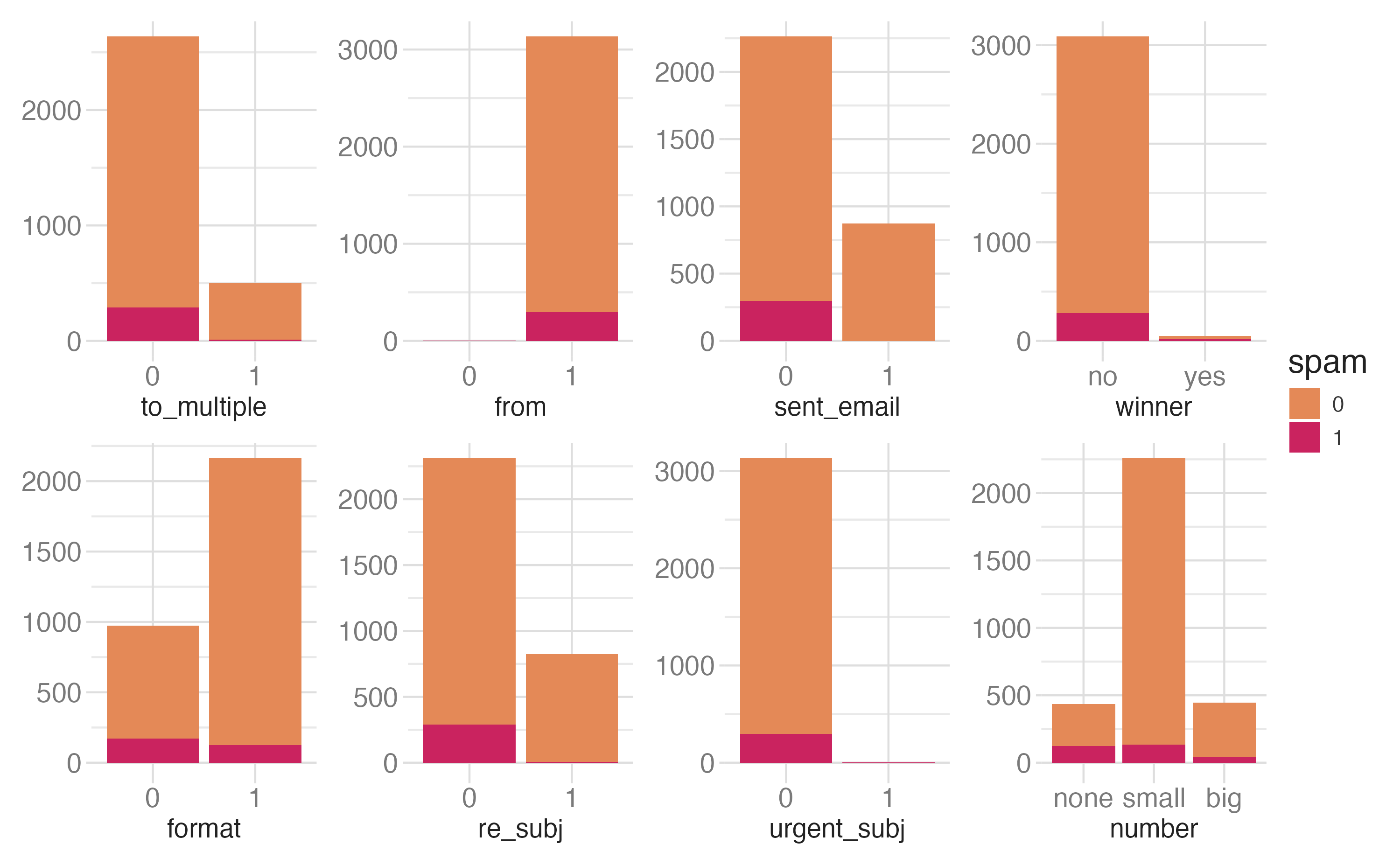
Categorical predictors
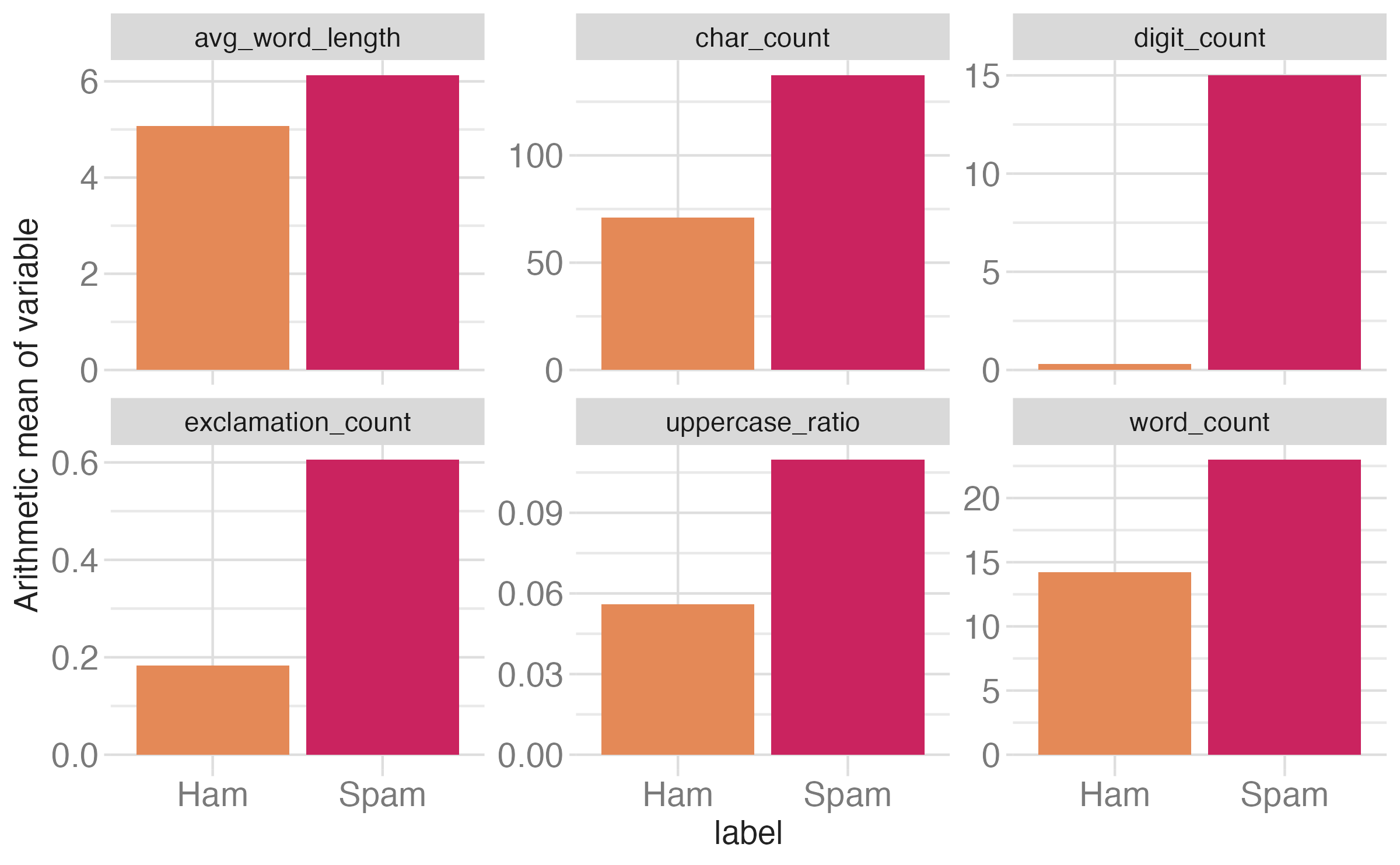
Numerical predictors
Predict outcome on the testing dataset
# A tibble: 1,186 × 18
.pred_class .pred_Ham .pred_Spam label url email phone char_count word_count avg_word_length
<fct> <dbl> <dbl> <fct> <chr> <chr> <chr> <int> <int> <dbl>
1 Ham 0.966 0.0344 Ham No No No 173 33 5.24
2 Ham 0.994 0.00599 Ham No No No 133 30 4.43
3 Ham 0.995 0.00512 Ham No No No 31 6 5.17
4 Ham 0.996 0.00404 Ham No No No 32 7 4.57
5 Ham 0.994 0.00627 Ham No No No 134 26 5.15
6 Ham 0.985 0.0147 Ham No No No 20 5 4
7 Spam 0.00270 0.997 Spam No No Yes 137 21 6.52
8 Spam 0.00374 0.996 Spam Yes No No 156 26 6
9 Ham 0.997 0.00331 Ham No No No 80 18 4.44
10 Ham 0.996 0.00360 Ham No No No 17 4 4.25
# ℹ 1,176 more rows
# ℹ 8 more variables: exclamation_count <int>, uppercase_ratio <dbl>, has_urgency_word <fct>,
# has_money_keyword <fct>, has_action_cta <fct>, has_org_name <fct>, digit_count <int>,
# has_shortlink <fct>Predict probabilities on the testing dataset
Evaluate the performance
Receiver operating characteristic (ROC) curve1 which plot true positive rate (sensitivity) vs. false positive rate (1 - specificity) across varying prediction thresholds
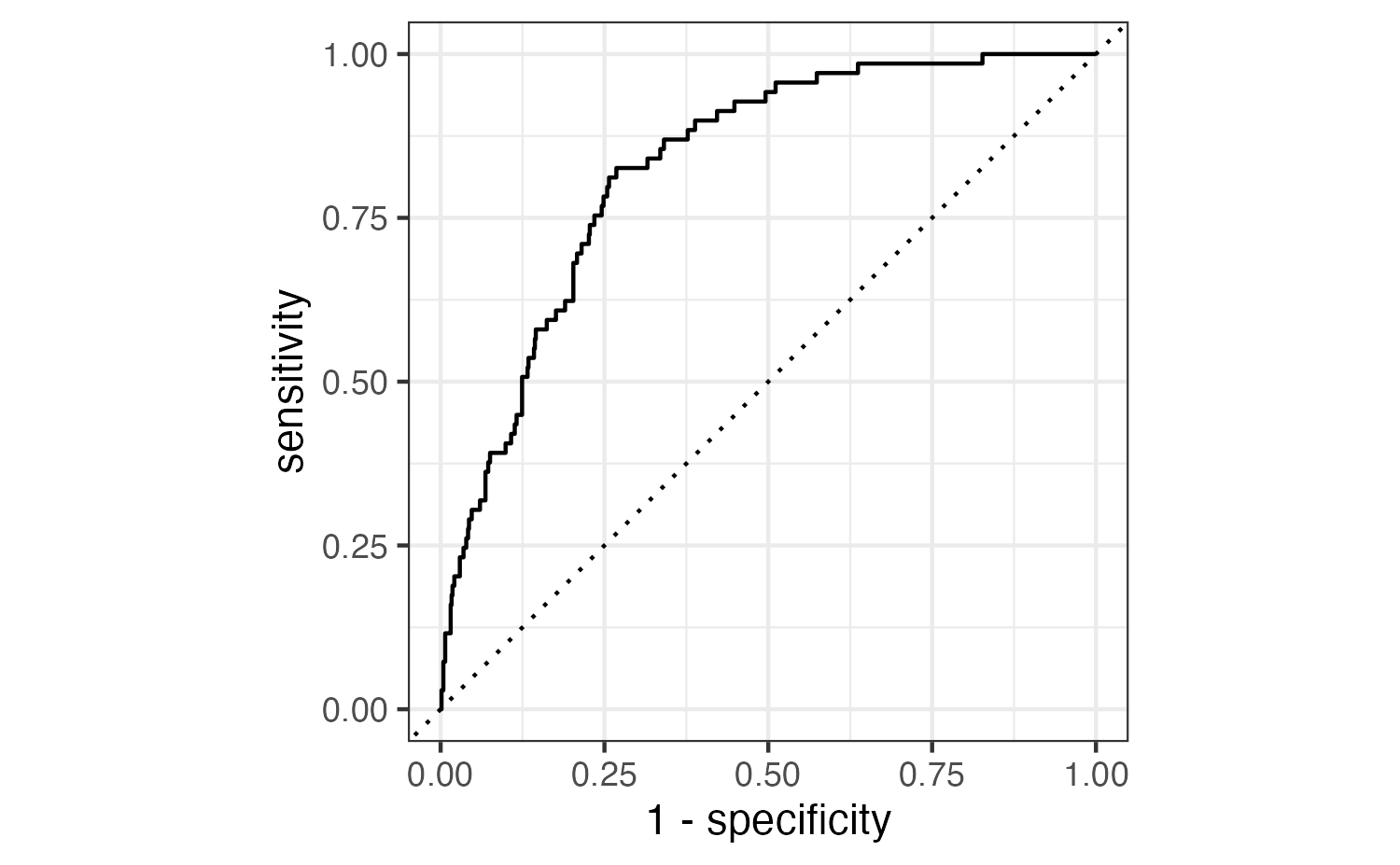
Evaluate the performance
Find the area under the curve:
Application exercise
Art history
Rows: 2,325
Columns: 24
$ artist_name <chr> "Aaron Douglas", "Aaron Douglas", "Aaron Douglas", "Aaron Douglas",…
$ edition_number <dbl> 9, 10, 11, 12, 13, 14, 15, 16, 14, 15, 16, 5, 6, 7, 8, 9, 10, 11, 1…
$ title_of_work <chr> "Noah's Ark", "Noah's Ark", "Noah's Ark", "Noah's Ark", "Noah's Ark…
$ publication_year <dbl> 1991, 1996, 2001, 2005, 2009, 2013, 2016, 2020, 2013, 2016, 2020, 1…
$ page_number_of_image <chr> "965", "1053", "1030", "990", "937", "867", "912", "932", "740", "7…
$ artist_unique_id <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4…
$ artist_nationality <chr> "American", "American", "American", "American", "American", "Americ…
$ artist_gender <chr> "Male", "Male", "Male", "Male", "Male", "Male", "Male", "Male", "Fe…
$ artist_race <chr> "Black or African American", "Black or African American", "Black or…
$ artist_ethnicity <chr> "Not Hispanic or Latinx", "Not Hispanic or Latinx", "Not Hispanic o…
$ height_of_work_in_book <dbl> 11.3, 12.1, 12.3, 12.3, 12.8, 12.8, 12.7, 7.9, 14.0, 12.8, 12.8, 10…
$ width_of_work_in_book <dbl> 8.5, 8.9, 8.8, 8.8, 9.3, 9.3, 9.2, 19.0, 10.2, 9.2, 9.2, 7.4, 7.3, …
$ height_of_text <dbl> 14.5, 12.4, 10.8, 15.7, 15.0, 18.8, 21.2, 14.7, 4.5, 16.2, 24.8, 9.…
$ width_of_text <dbl> 8.4, 9.0, 9.0, 8.9, 9.3, 9.3, 9.2, 13.9, 9.3, 9.2, 9.3, 6.9, 7.0, 8…
$ extra_text_height <dbl> 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 9.2, 0.0, 0.0, 0.0, 0.0, 0.…
$ extra_text_width <dbl> 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 8.8, 0.0, 0.0, 0.0, 0.0, 0.…
$ area_of_work_in_book <dbl> 96.05, 107.69, 108.24, 108.24, 119.04, 119.04, 116.84, 150.10, 142.…
$ area_of_text <dbl> 121.80, 111.60, 97.20, 139.73, 139.50, 174.84, 195.04, 204.33, 41.8…
$ extra_text_area <dbl> 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 80.96, 0.00, 0.00, …
$ total_area_text <dbl> 121.80, 111.60, 97.20, 139.73, 139.50, 174.84, 195.04, 204.33, 122.…
$ total_space <dbl> 217.85, 219.29, 205.44, 247.97, 258.54, 293.88, 311.88, 354.43, 265…
$ page_area <dbl> 616.500, 586.420, 677.440, 657.660, 648.930, 648.930, 646.700, 651.…
$ space_ratio_per_page <dbl> 0.3533658, 0.3739470, 0.3032593, 0.3770489, 0.3984097, 0.4528686, 0…
$ book <chr> "gardner", "gardner", "gardner", "gardner", "gardner", "gardner", "…
ae-18
Instructions
- Go to the course GitHub org and find your
ae-18(repo name will be suffixed with your GitHub name). - Clone the repo in Positron, run
renv::restore()to install the required packages, open the Quarto document in the repo, and follow along and complete the exercises. - Render, commit, and push your edits by the AE deadline – end of the day
Wrap up
Recap
- Generalized linear models allow us to fit models to predict non-continuous outcomes
- Predicting binary outcomes requires modeling the log-odds of success, where p = probability of success
- Interpreting logistic regression coefficients requires calculating predicted probabilities
- Use training/test set splits to prevent overfitting
- Use appropriate metrics to evaluate model performance
- The decision threshold effects the predictions generated from a logistic regression model
Acknowledgments
- Draws upon material from Data Science in a Box licensed under Creative Commons Attribution-ShareAlike 4.0 International