# A tibble: 146 × 3
film critics audience
<chr> <int> <int>
1 Avengers: Age of Ultron 74 86
2 Cinderella 85 80
3 Ant-Man 80 90
4 Do You Believe? 18 84
5 Hot Tub Time Machine 2 14 28
6 The Water Diviner 63 62
7 Irrational Man 42 53
8 Top Five 86 64
9 Shaun the Sheep Movie 99 82
10 Love & Mercy 89 87
# ℹ 136 more rowsLinear regression with a single predictor
Lecture 18
March 24, 2026
Modeling
- Use models to explain the relationship between variables and to make predictions
- Many different types of models
- Linear models – classic forms used for statistical inference
- Nonlinear models – much more common in machine learning for prediction
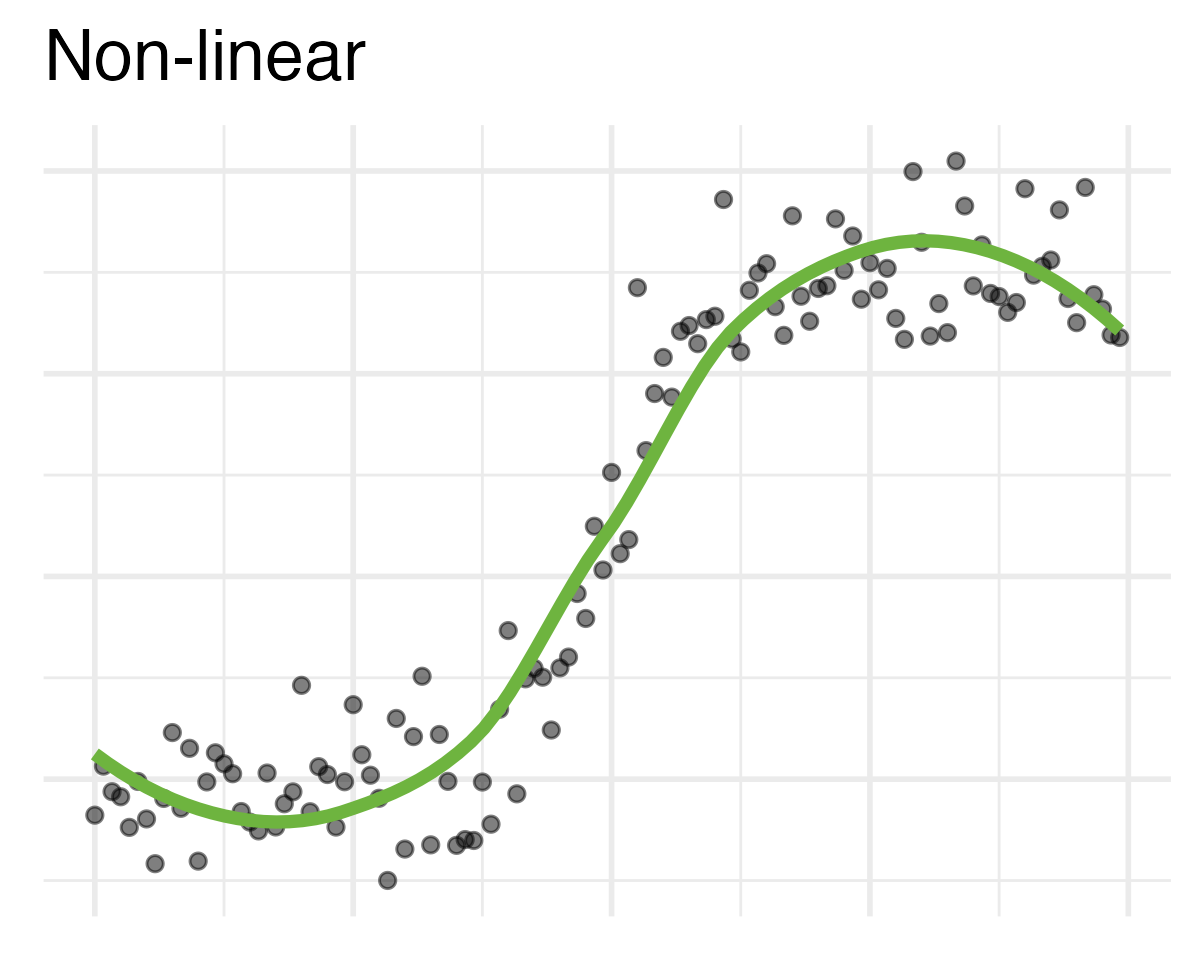
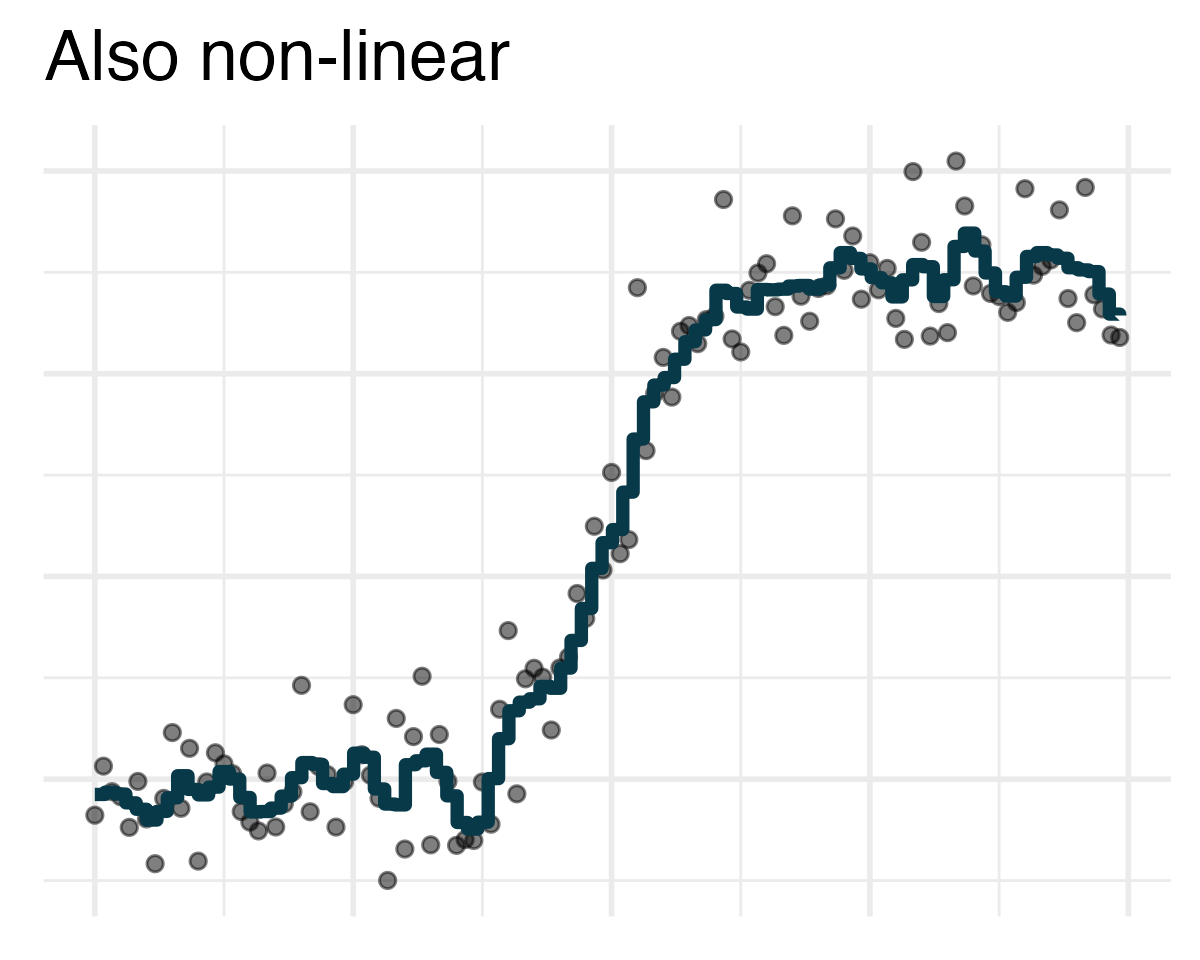
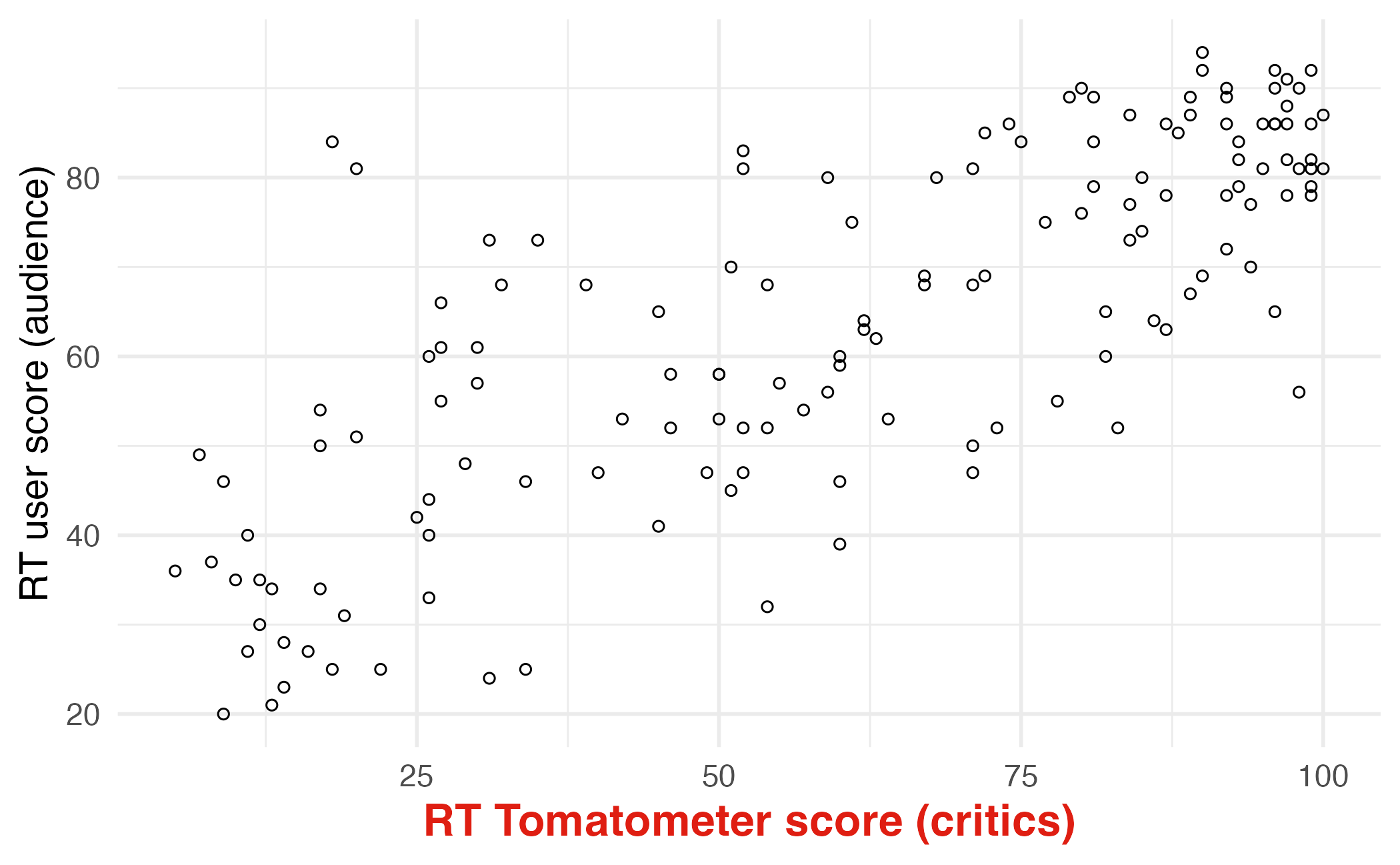
Modeling film ratings
- What is the relationship between the critics and audience scores for films?
- What is your best guess for a film’s audience score if the critics rated it a 73?
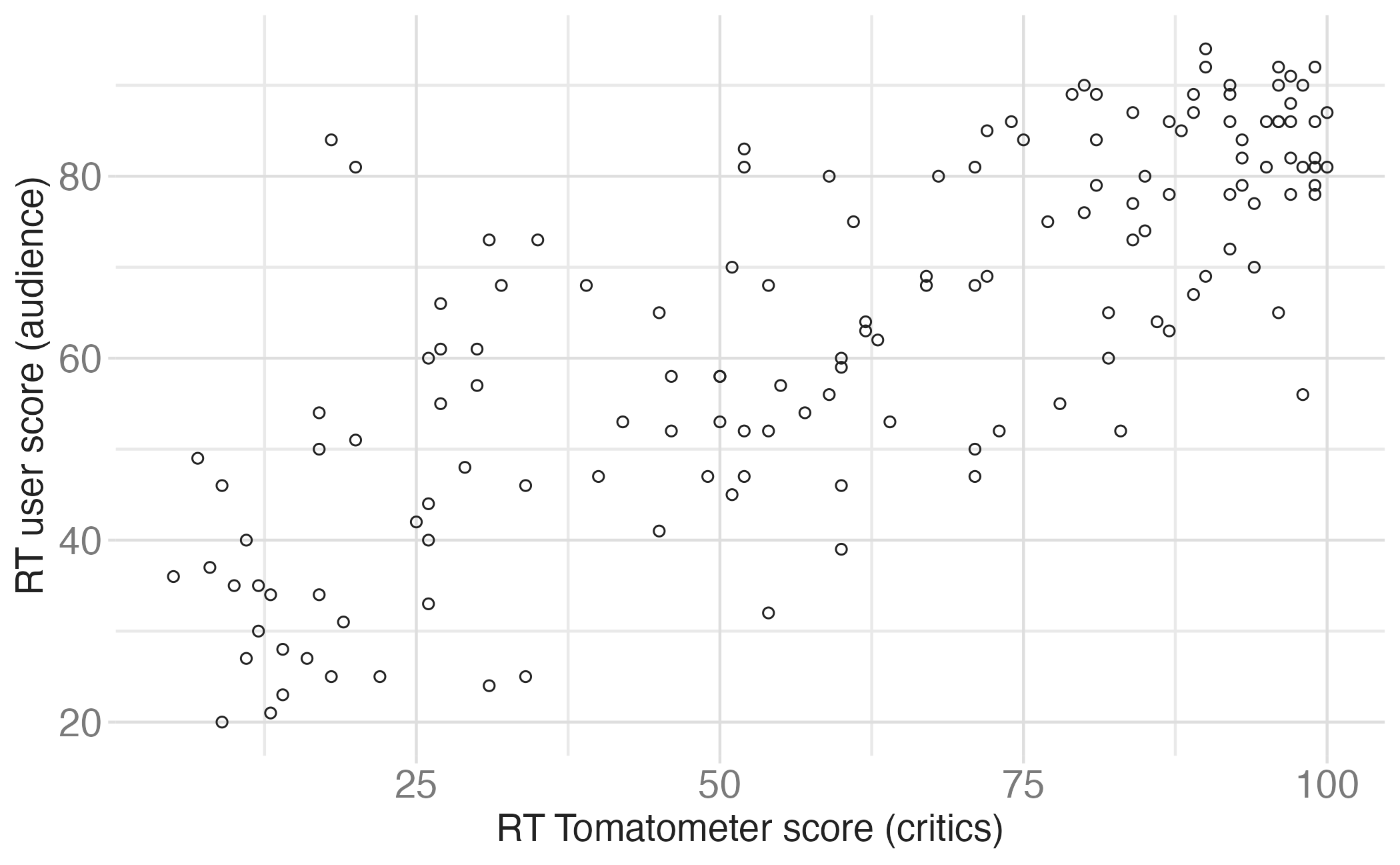
Predictor (explanatory variable)
| audience | critics |
|---|---|
| 86 | 74 |
| 80 | 85 |
| 90 | 80 |
| 84 | 18 |
| 28 | 14 |
| 62 | 63 |
| ... | ... |
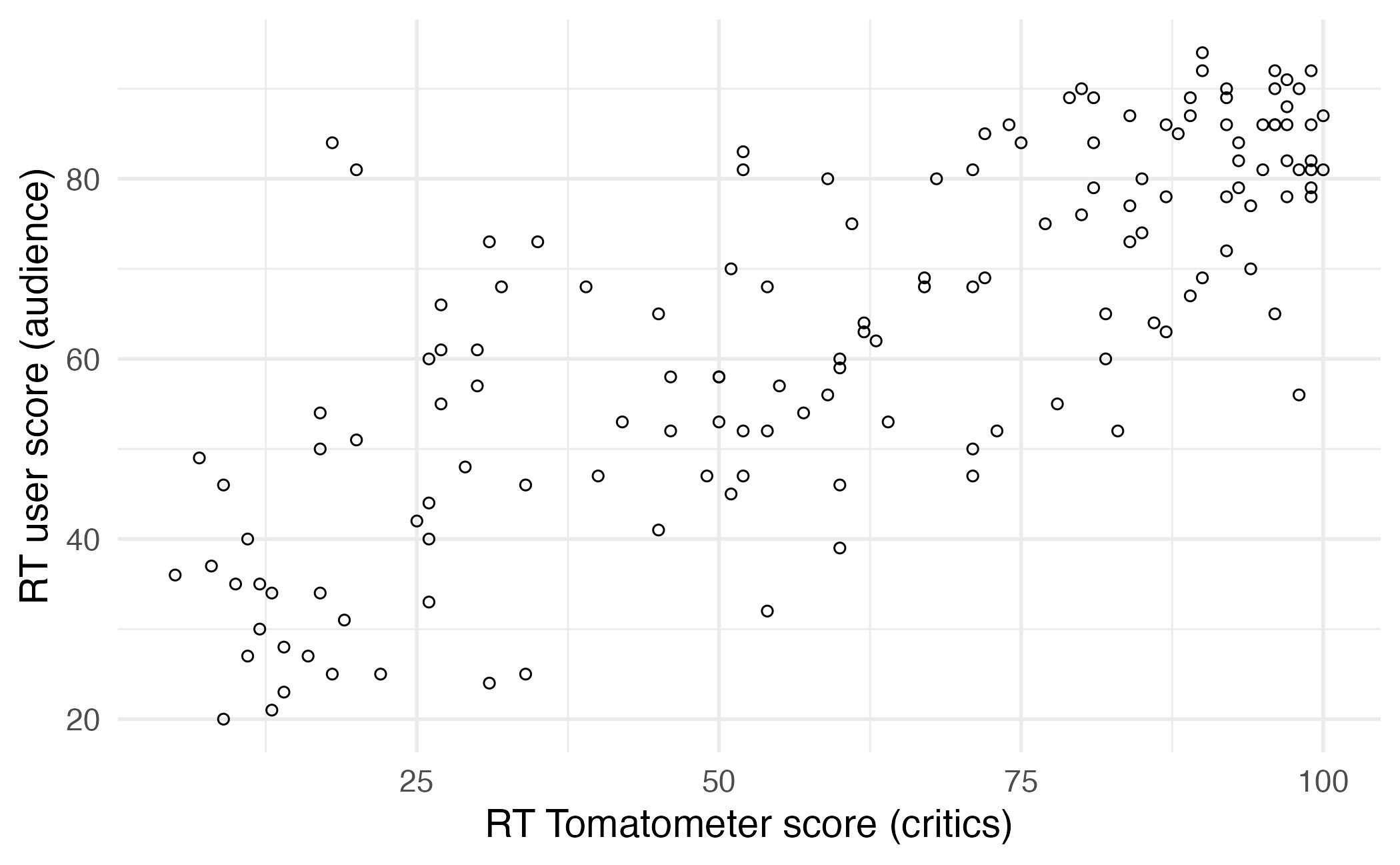
Outcome (response variable)
| audience | critics |
|---|---|
| 86 | 74 |
| 80 | 85 |
| 90 | 80 |
| 84 | 18 |
| 28 | 14 |
| 62 | 63 |
| ... | ... |
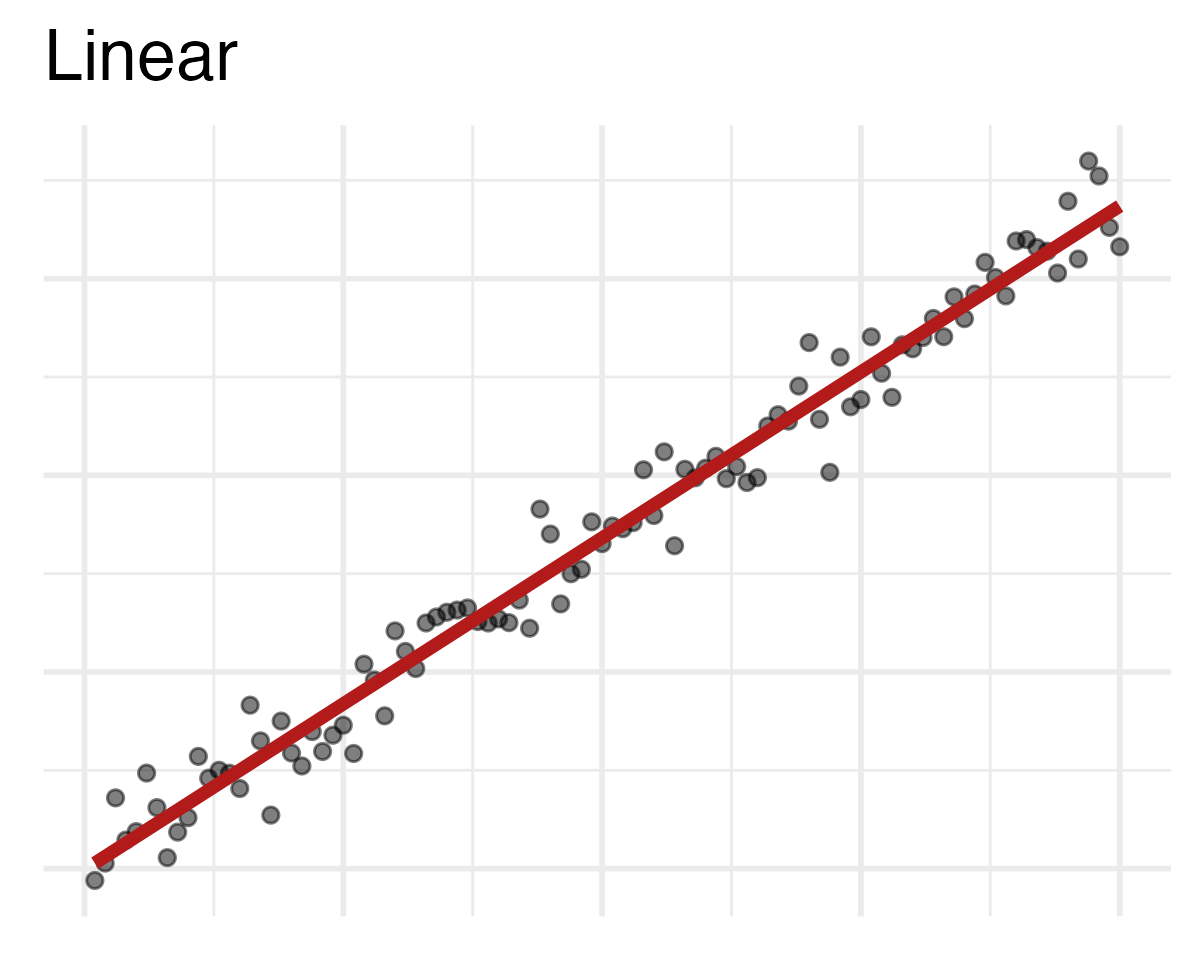
Regression line
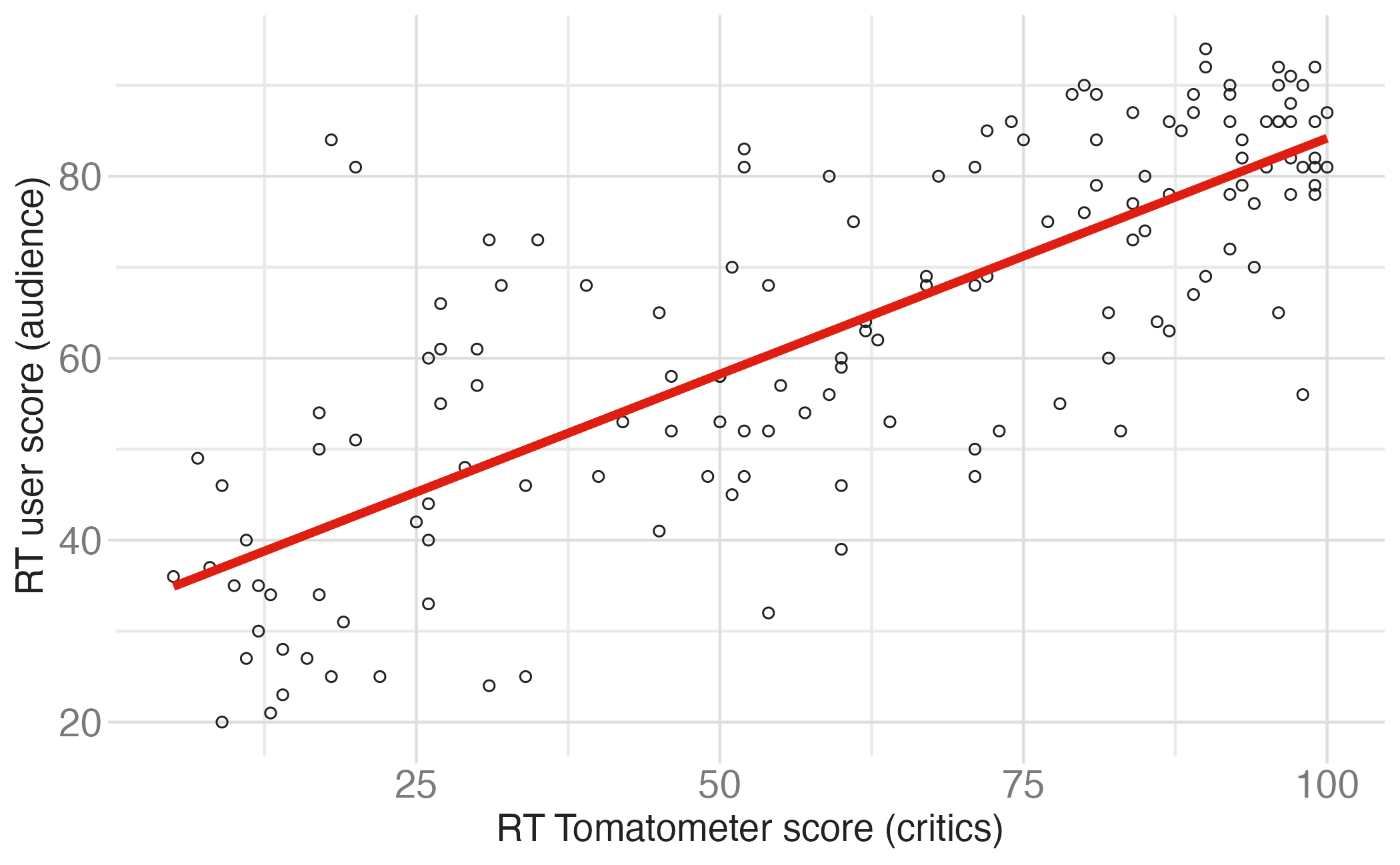
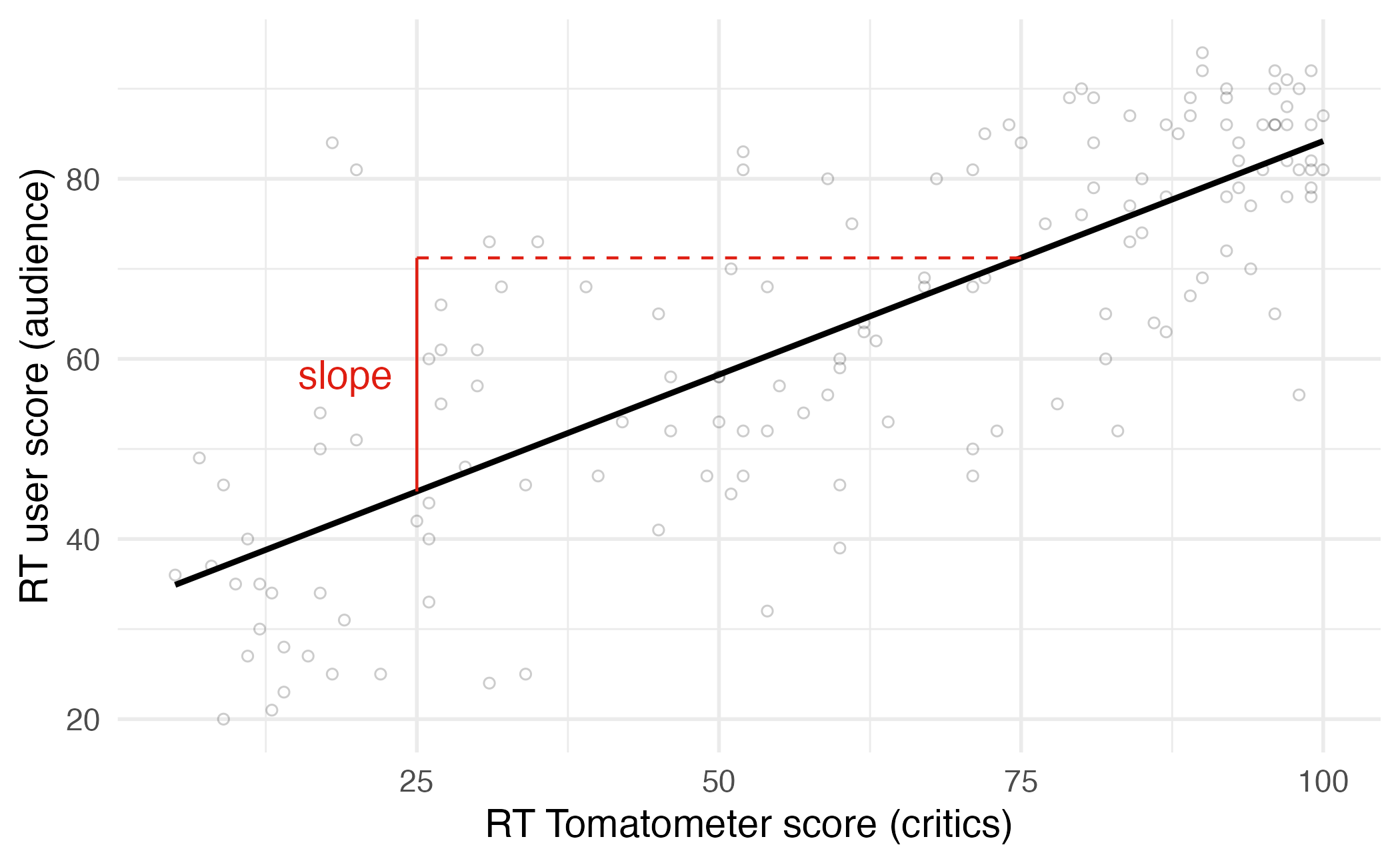
Regression line: slope
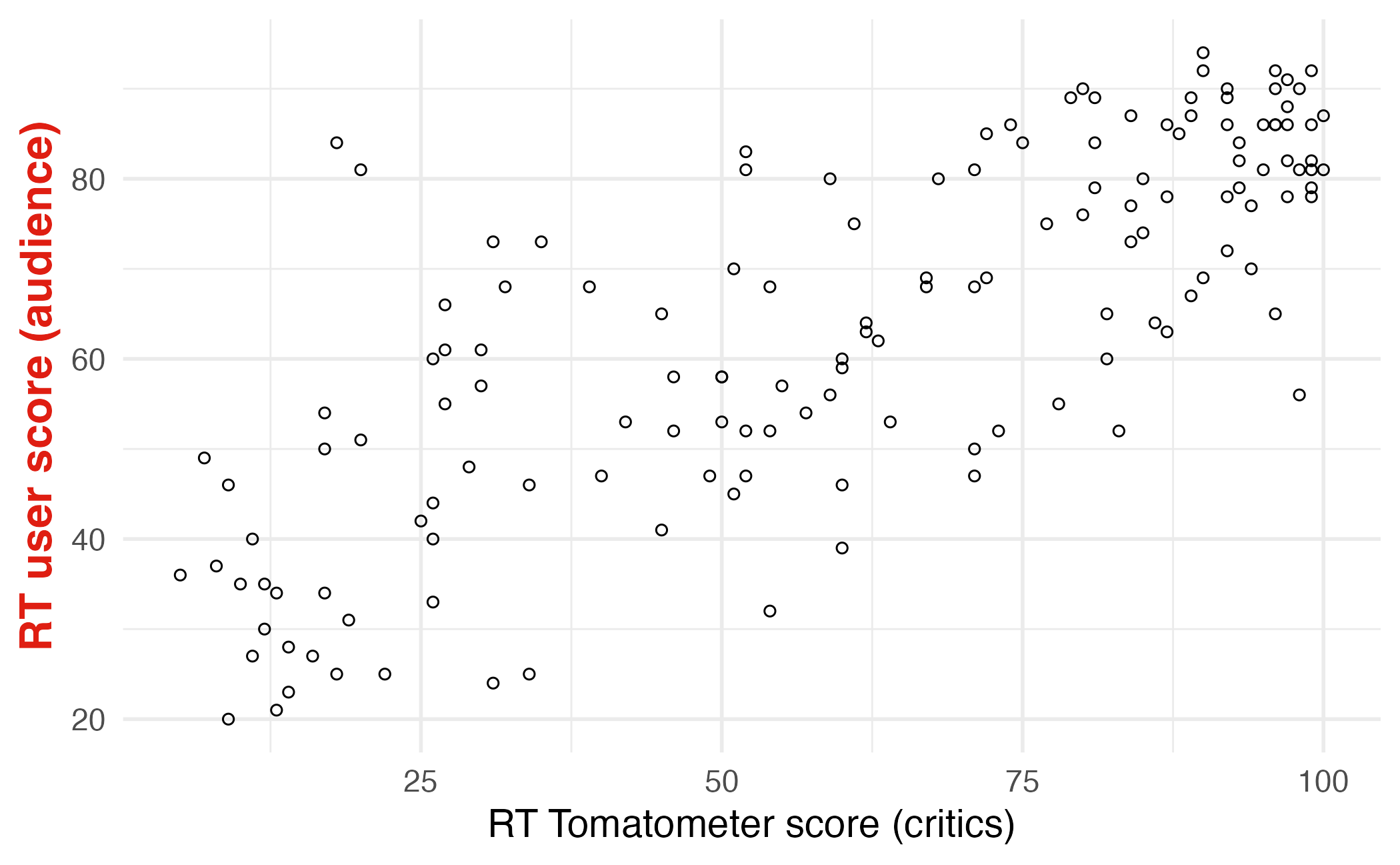
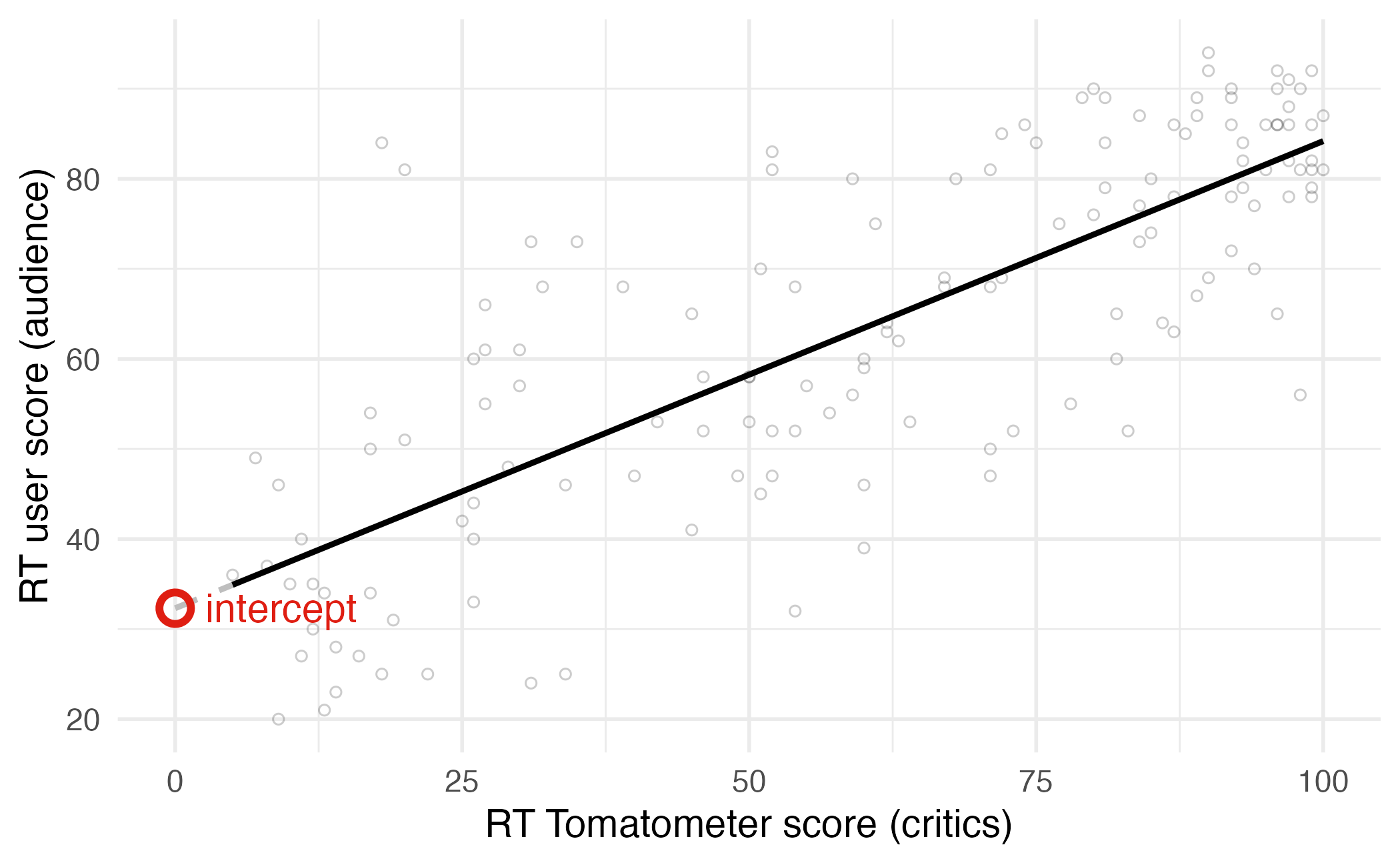
Regression line: intercept
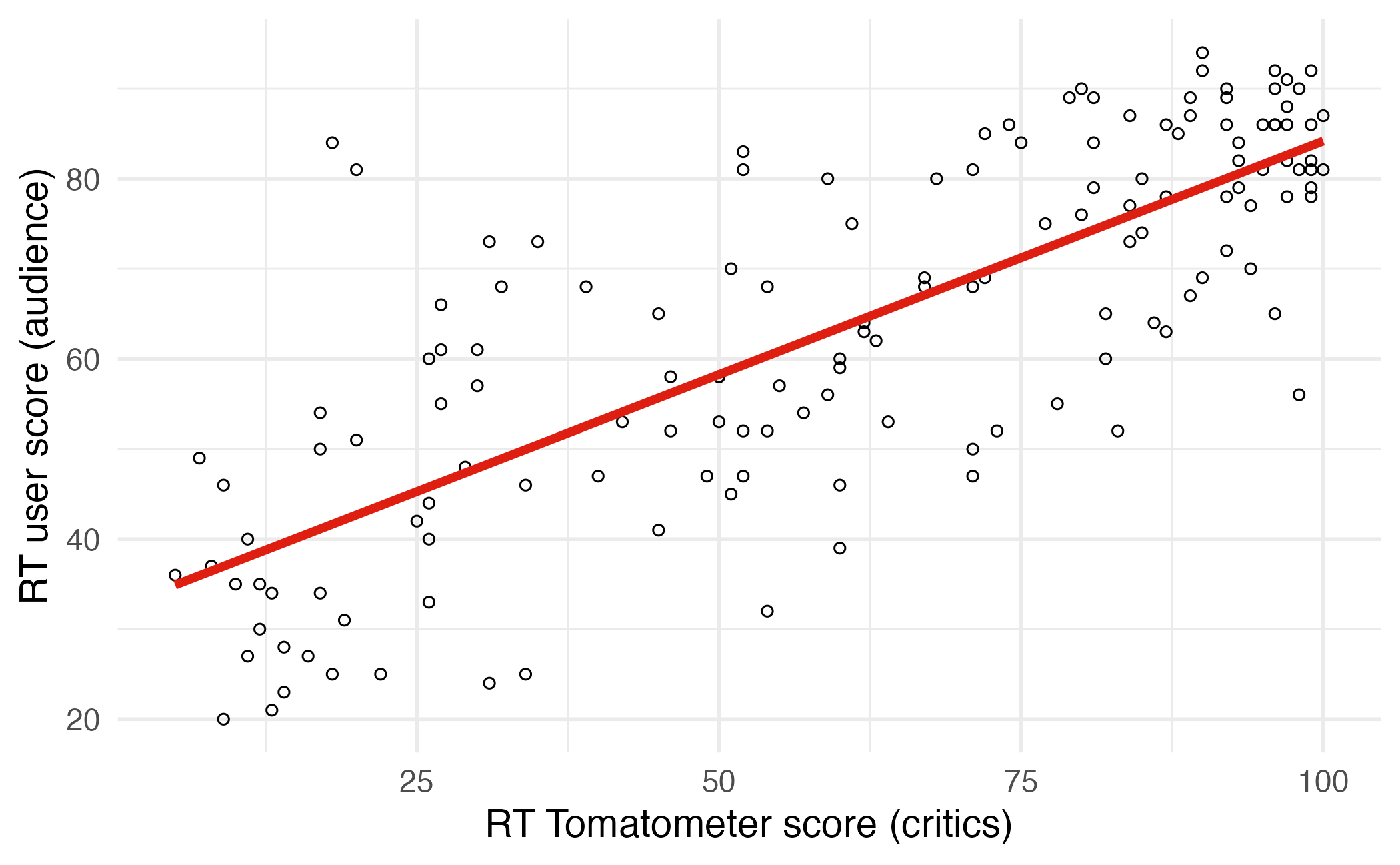
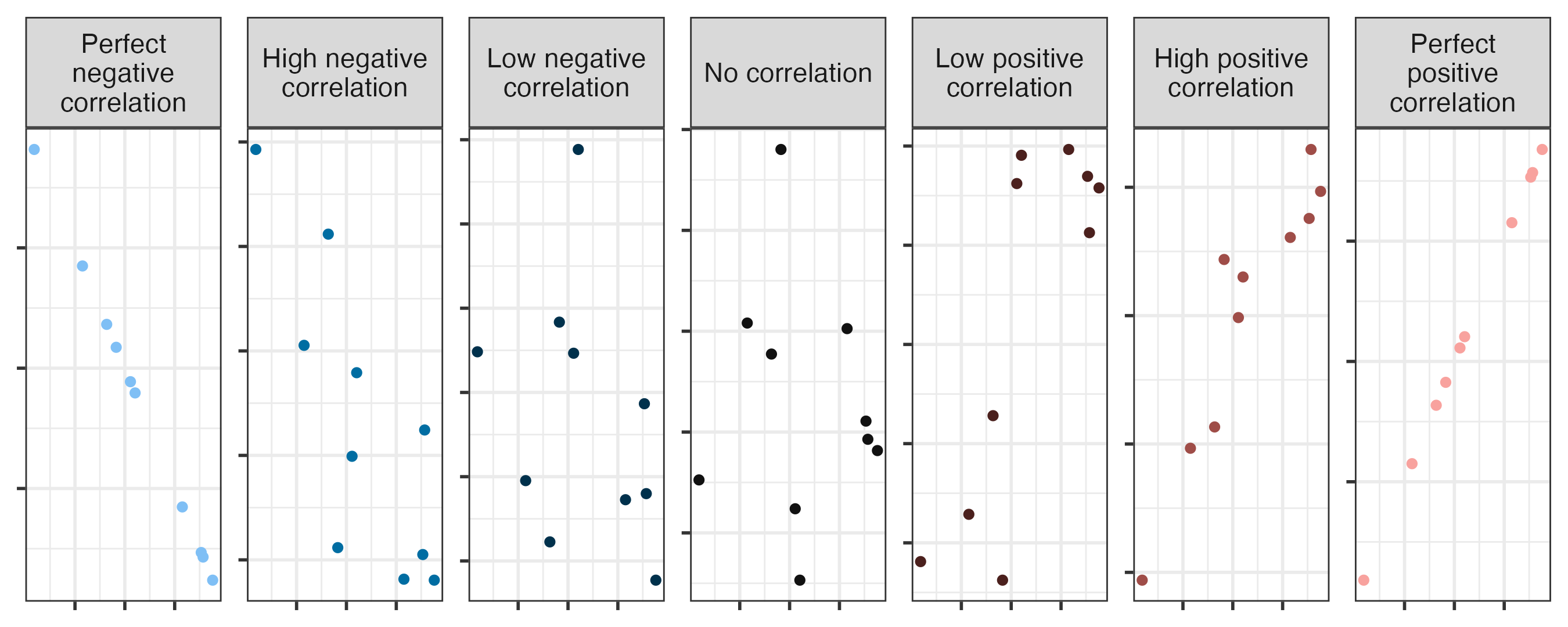
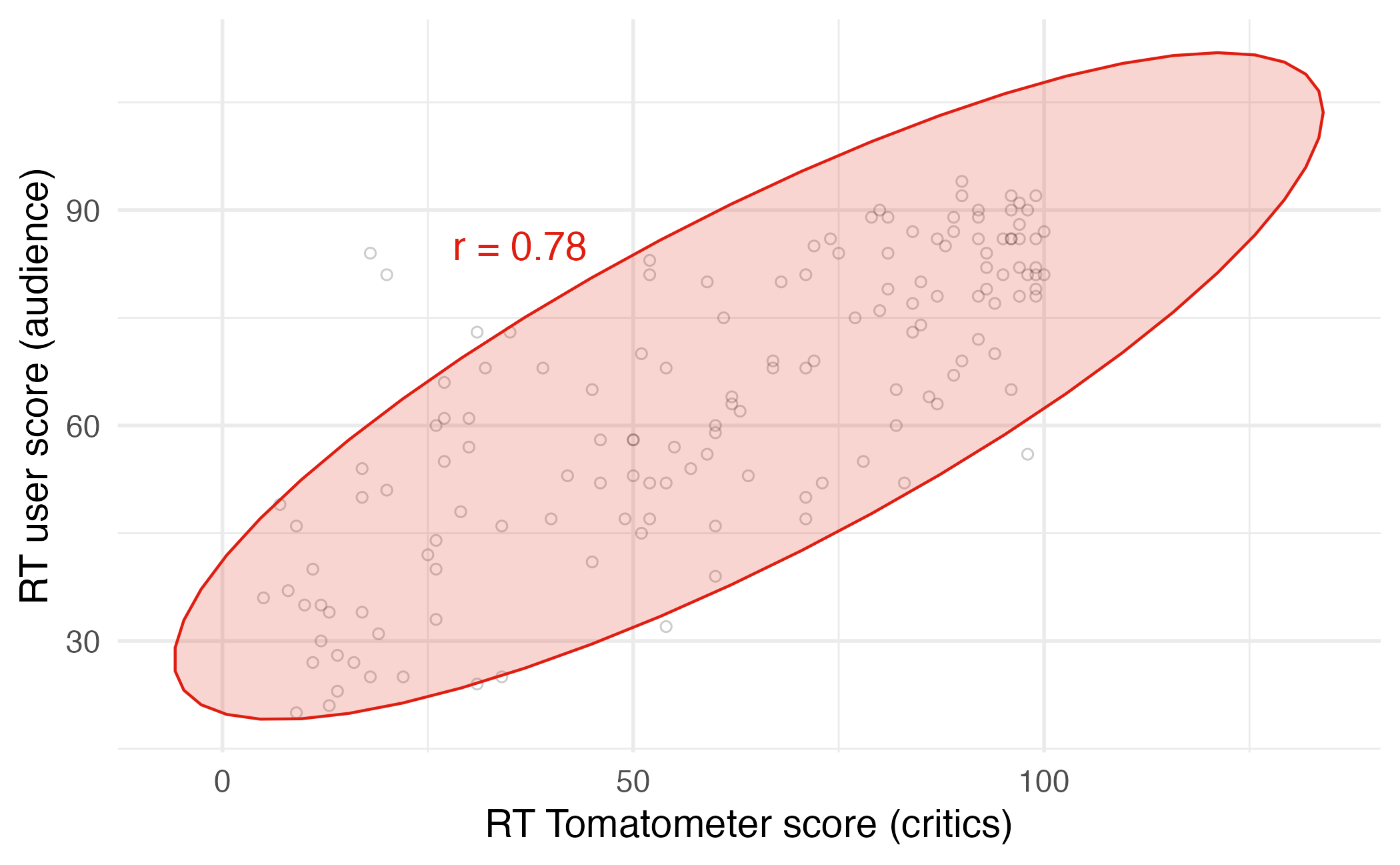
Correlation
Correlation
- Ranges between -1 and 1.
- Same sign as the slope.
Regression model
\[ \begin{aligned} Y &= \color{#DF1E12}{\textbf{Model}} + \text{Error} \\ &= \color{#DF1E12}{\mathbf{f(X)}} + \epsilon \end{aligned} \]
Residuals
\[\text{residual} = \text{observed} - \text{predicted} = y - \hat{y}\]
Permutation-based approach
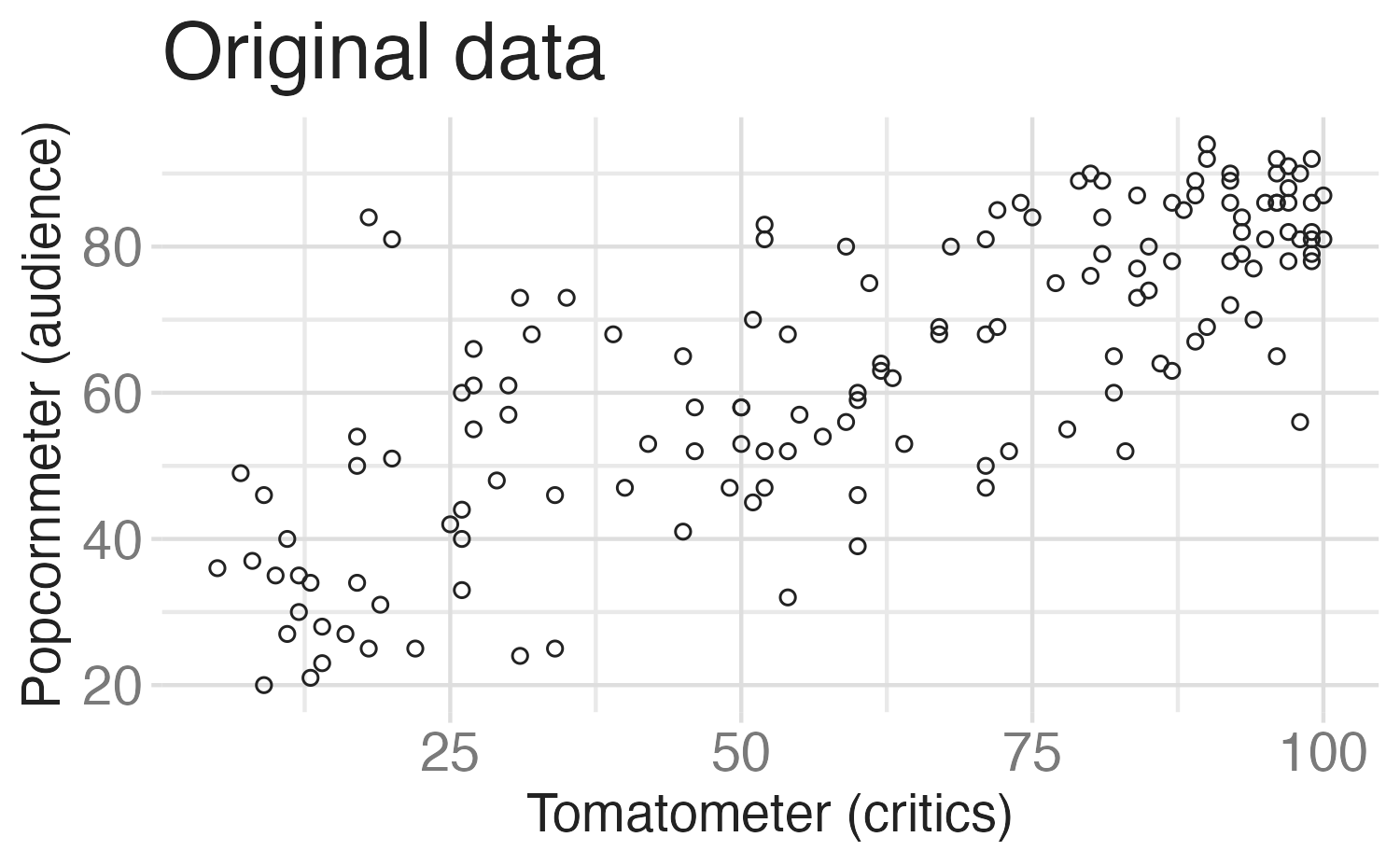
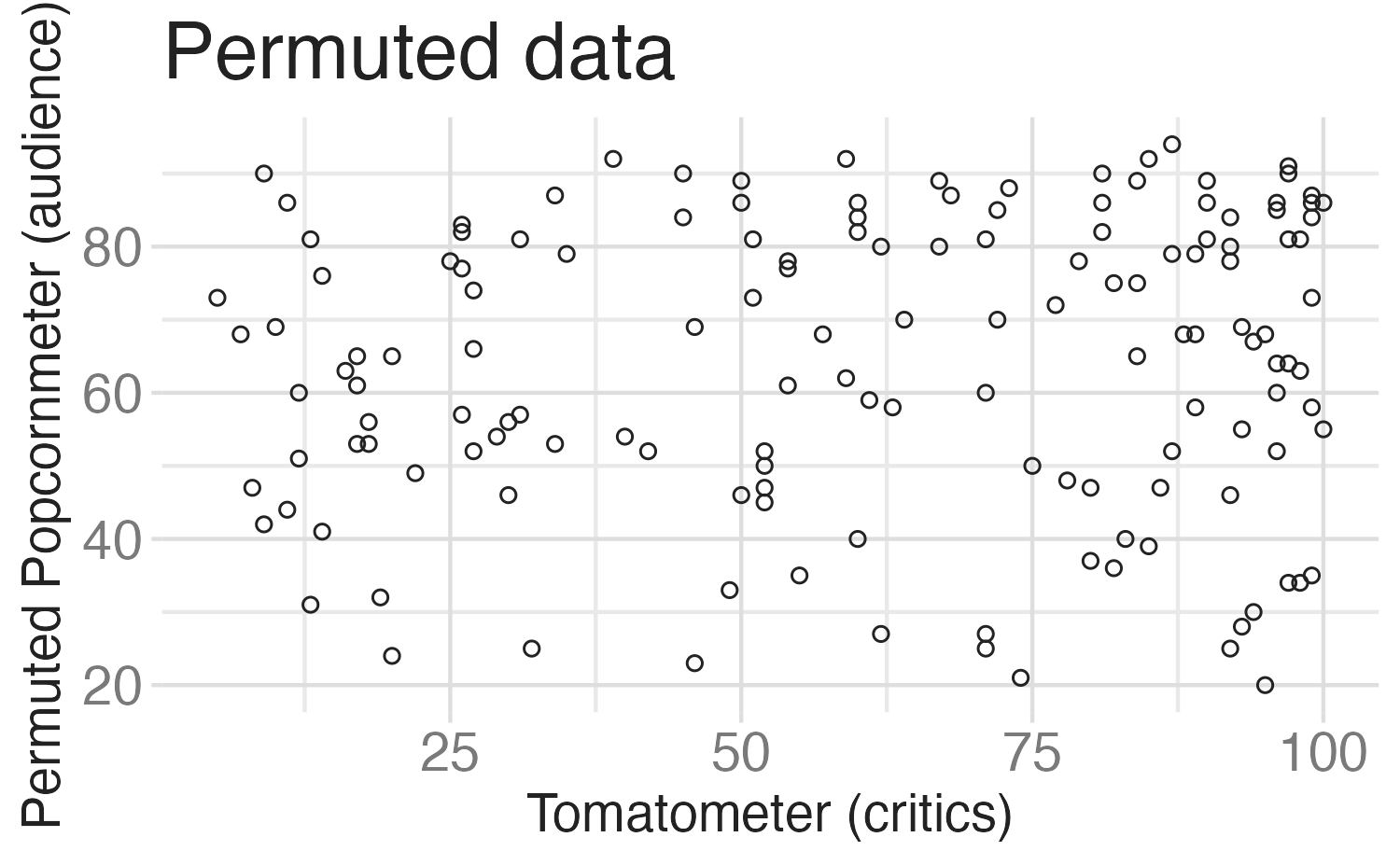
Variability of the statistic
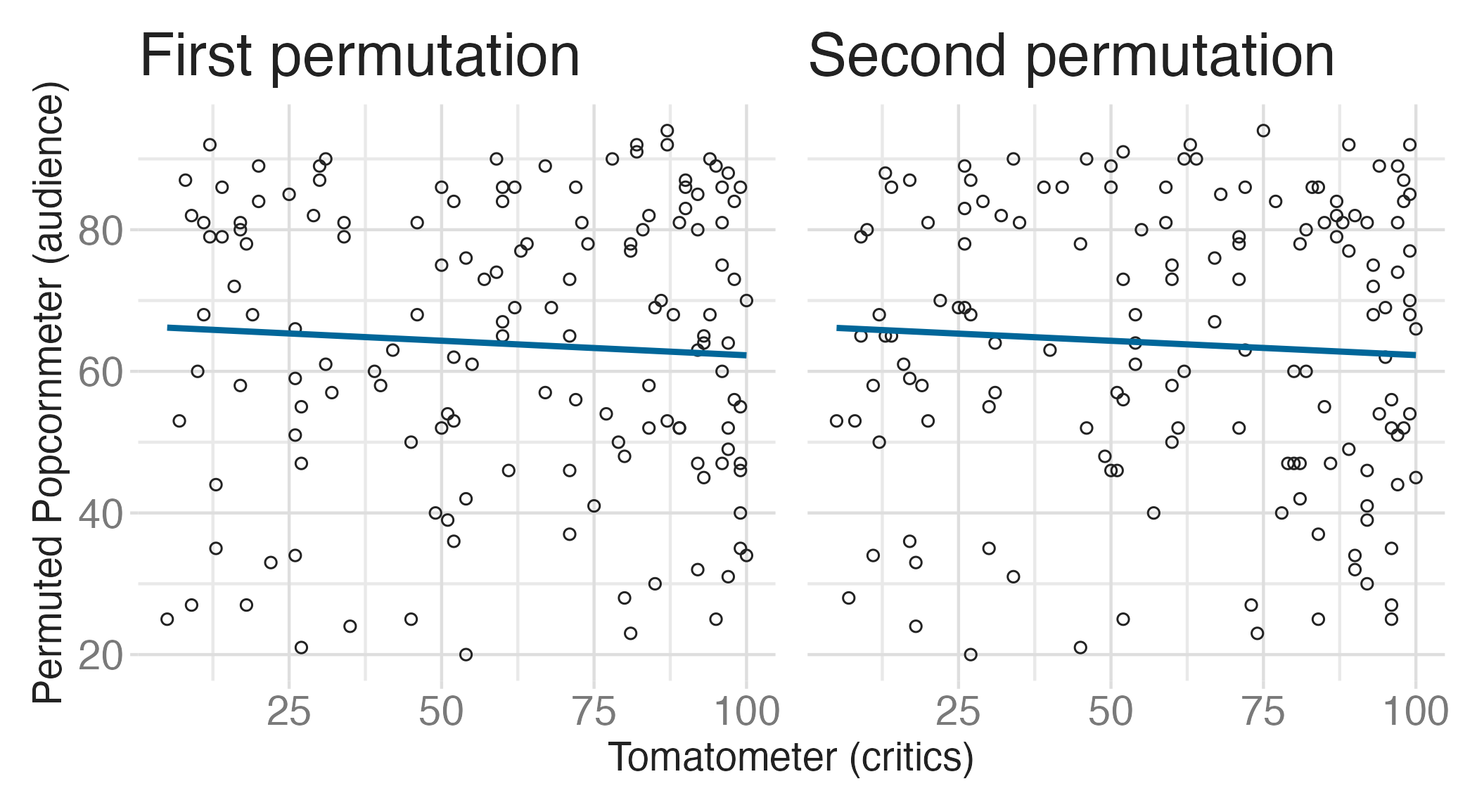
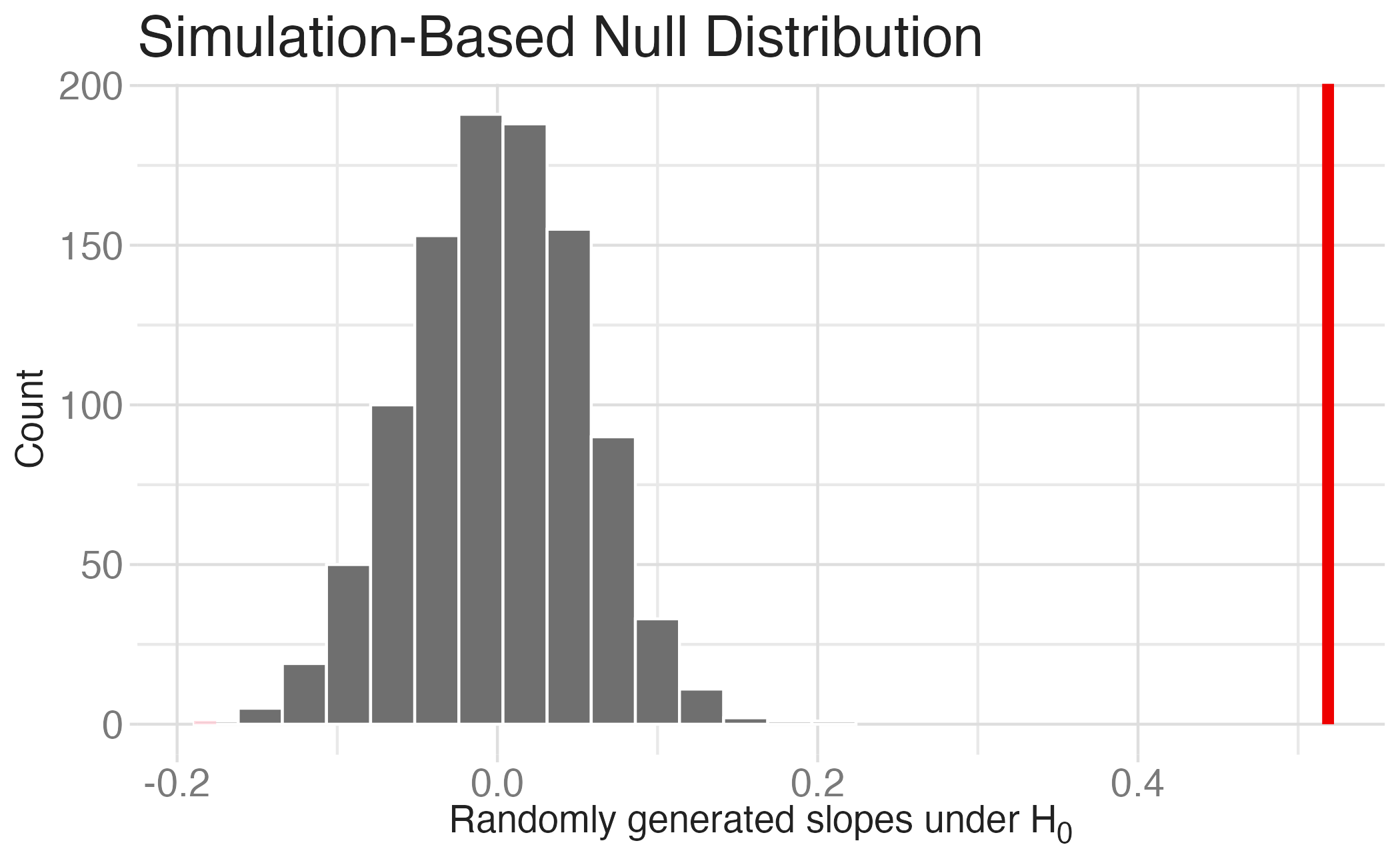
Observed statistic vs. null statistics
Bootstrap resampling
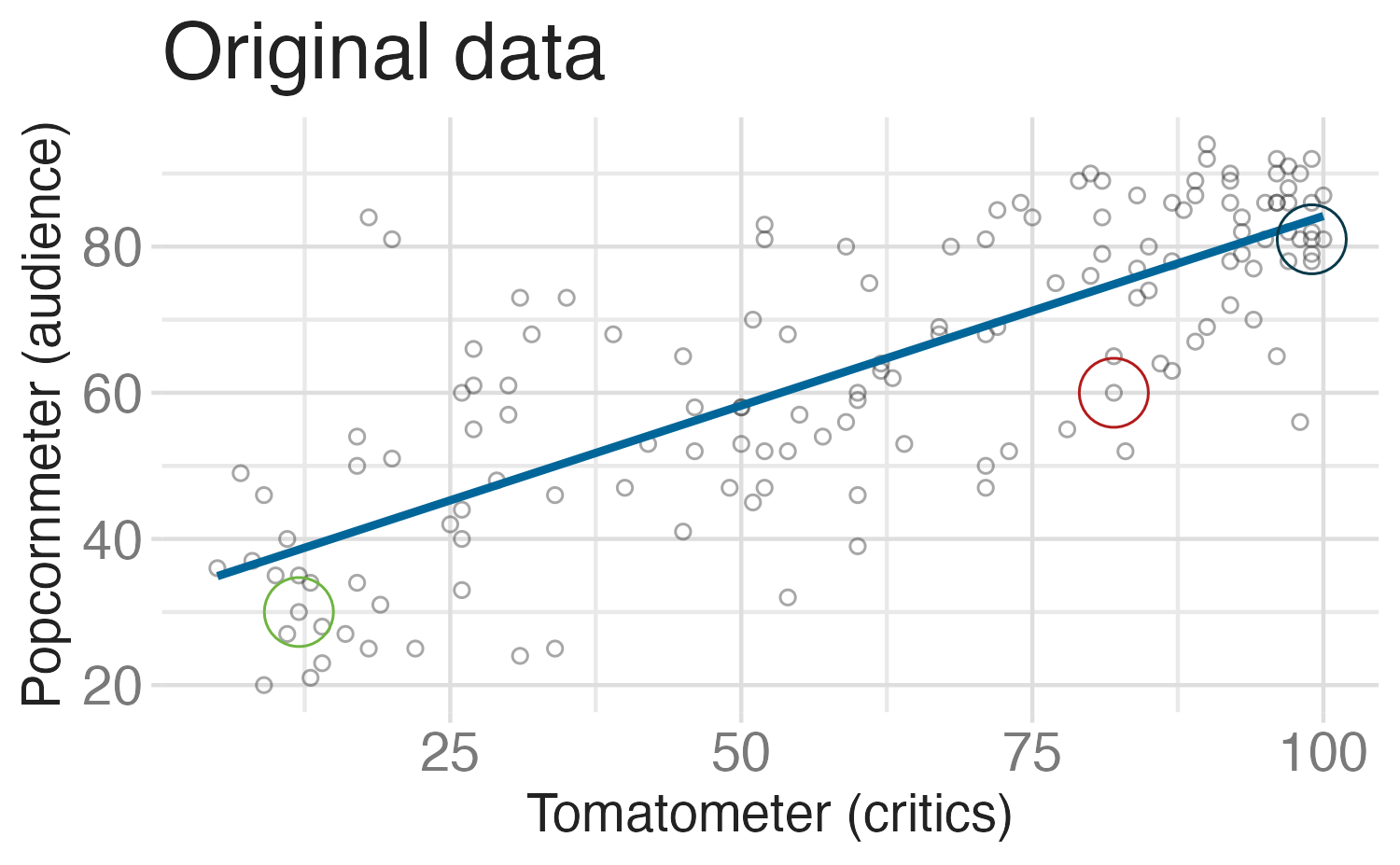
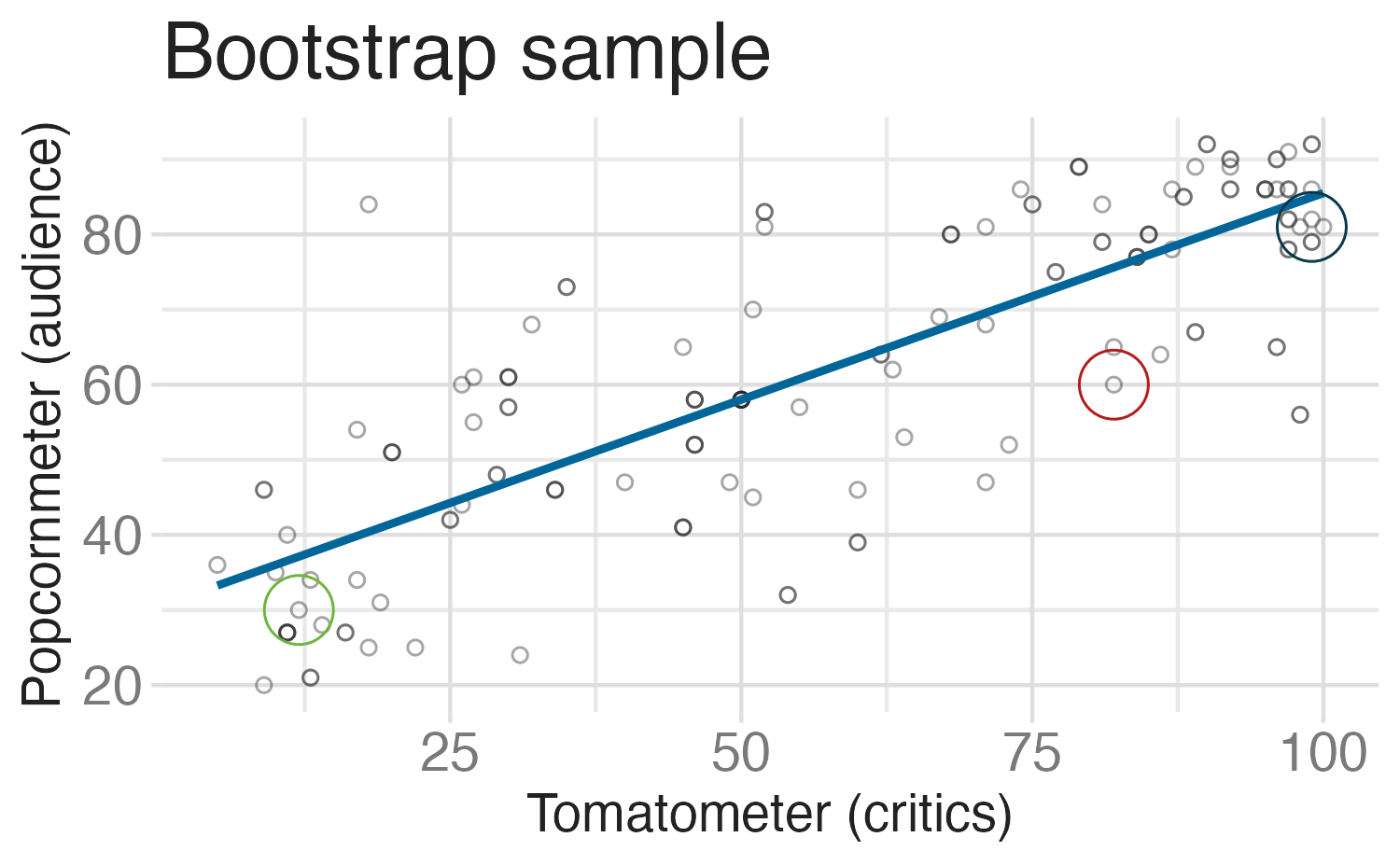
Bootstrap resampling (repeated)
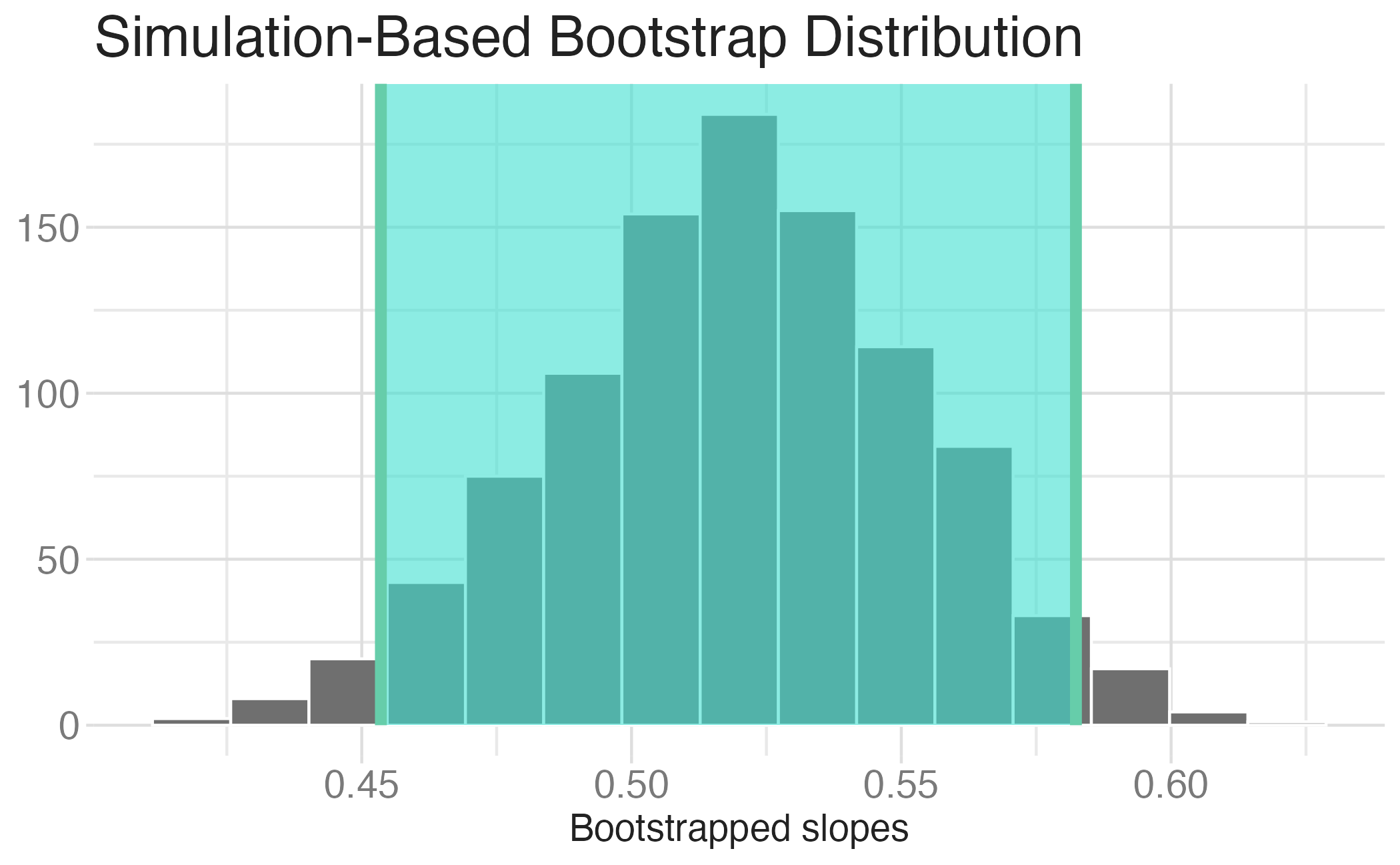
Bootstrap CI for the slope
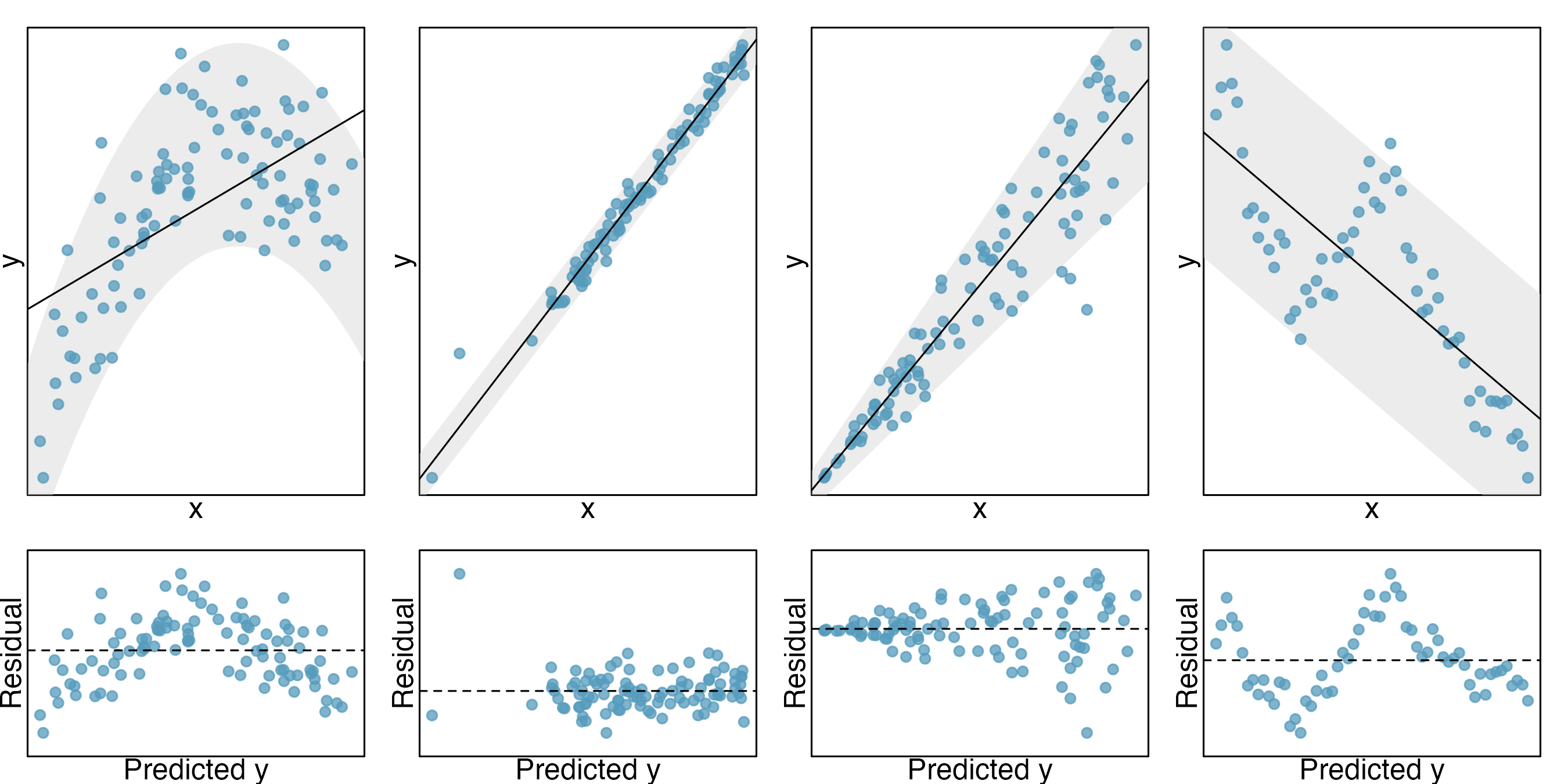
Violations of model conditions