Scraping data from the web
Lecture 11
February 27, 2025
{rvest}
- The {rvest} package makes basic processing and manipulation of HTML data straight forward
- It’s designed to work with pipelines built with
|> - rvest.tidyverse.org

Goal
- Scrape data and organize it in a tidy format in R
- Perform light text parsing to clean data
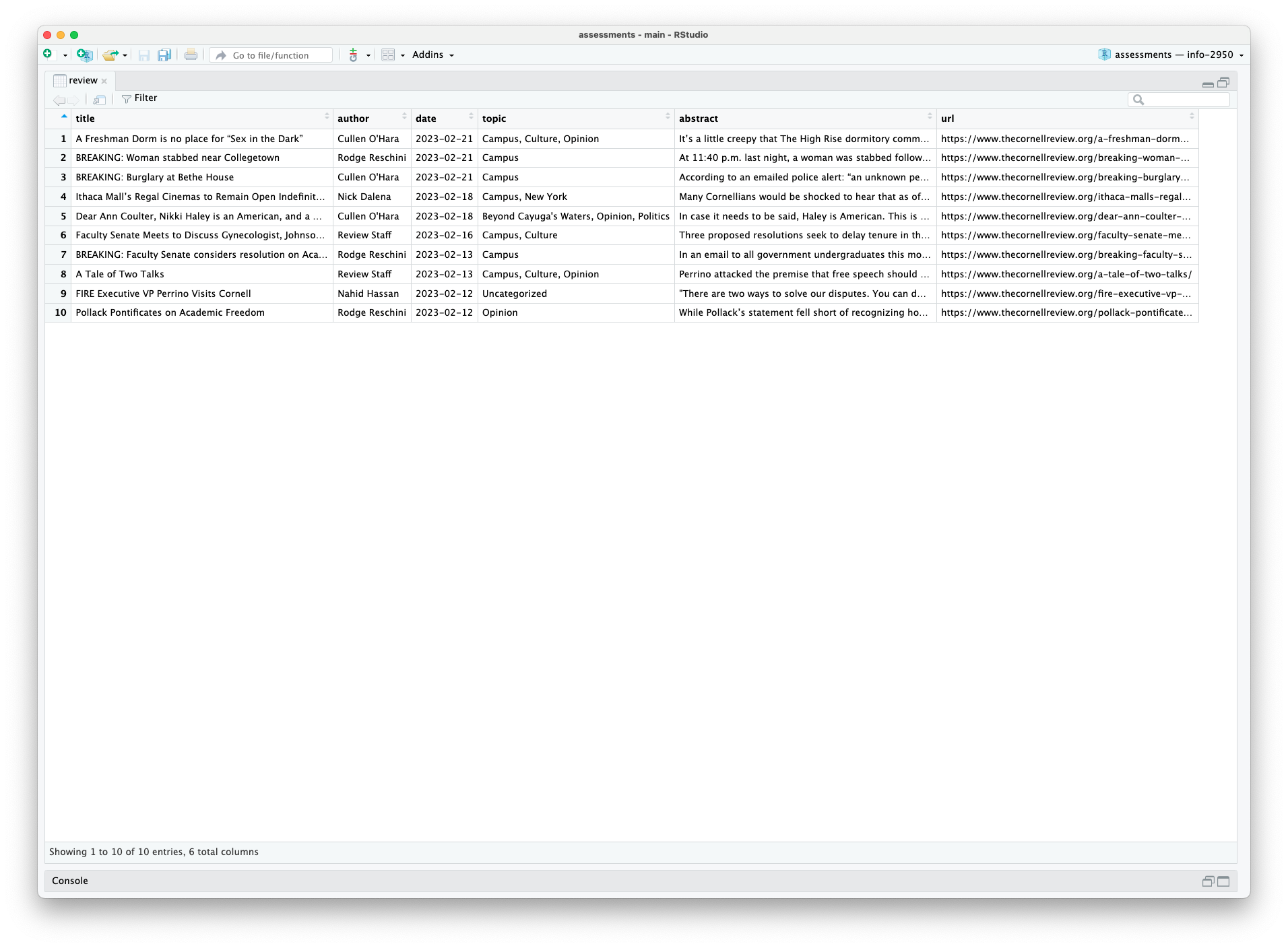
Ethics: “Can you?” vs “Should you?”
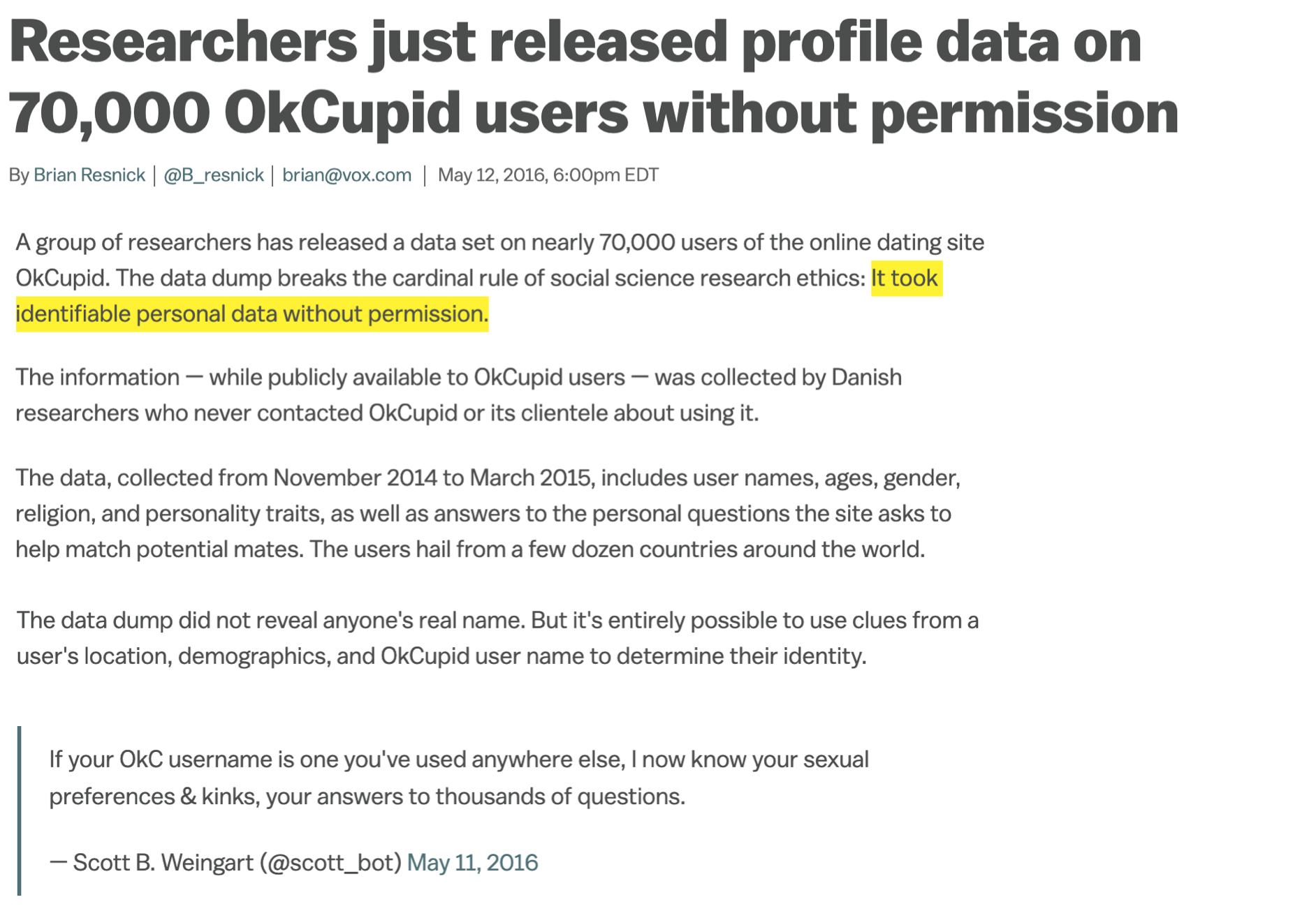
“Can you?” vs “Should you?”
Challenges: Unreliable formatting
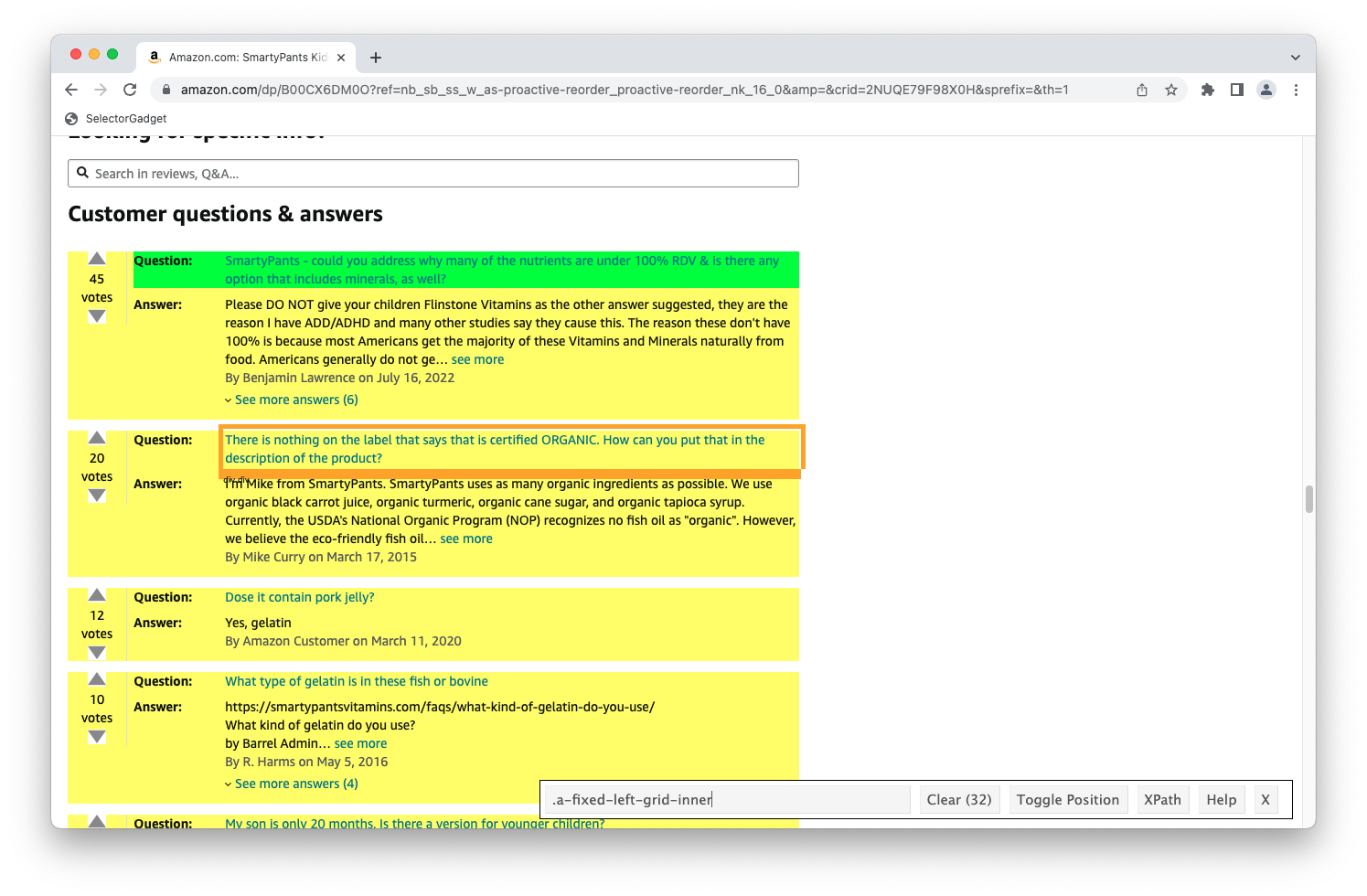
Challenges: Data broken into many pages
Our backyard deer
